Overview
Kernels are especially needed when we are dealing with non-linearly separable data and non-linear data. Consider the following situation:
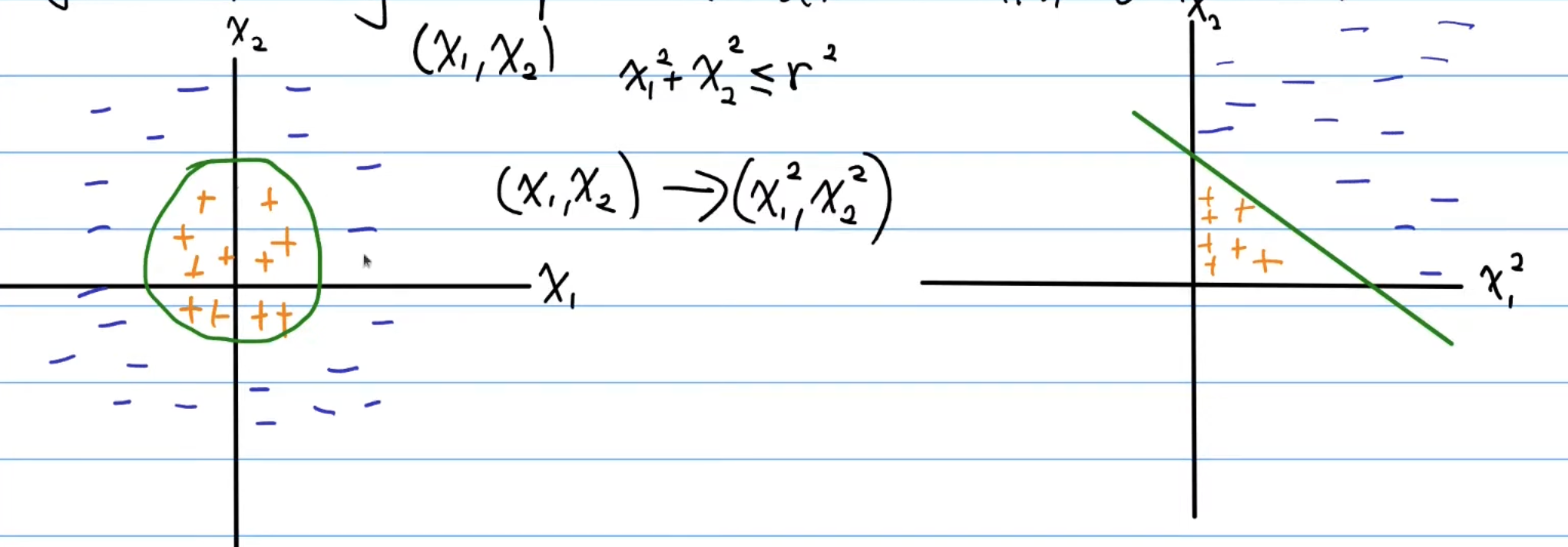
Now, the data on the left cannot be classified using a hyperplane, since the decision boundary is non-linear. We notice that if we were to draw one, one reasonable idea is it to just draw a circle around the data, with the equation of the circle. Now, let’s apply a non-linear transformation to the data. This function , transforms the left data points into the right, which is now linearly separable. Ok, thats cool, but same dimension transformations aren’t always feasible like this. A classic example of this is XOR:
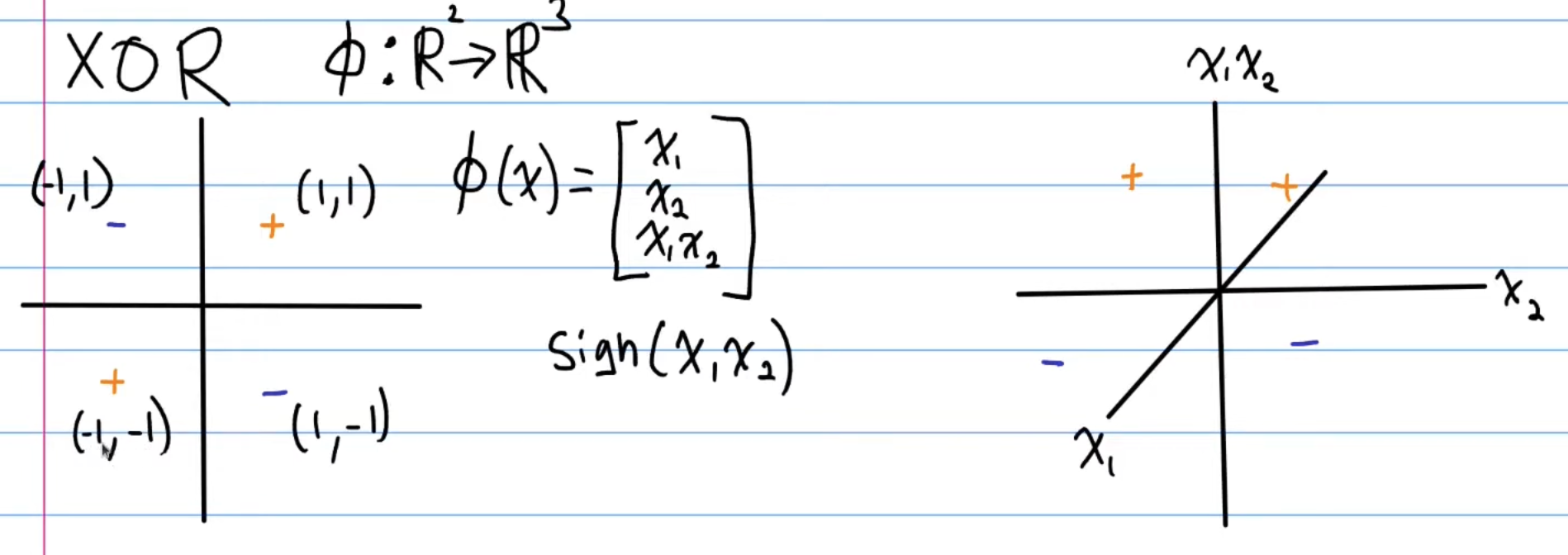
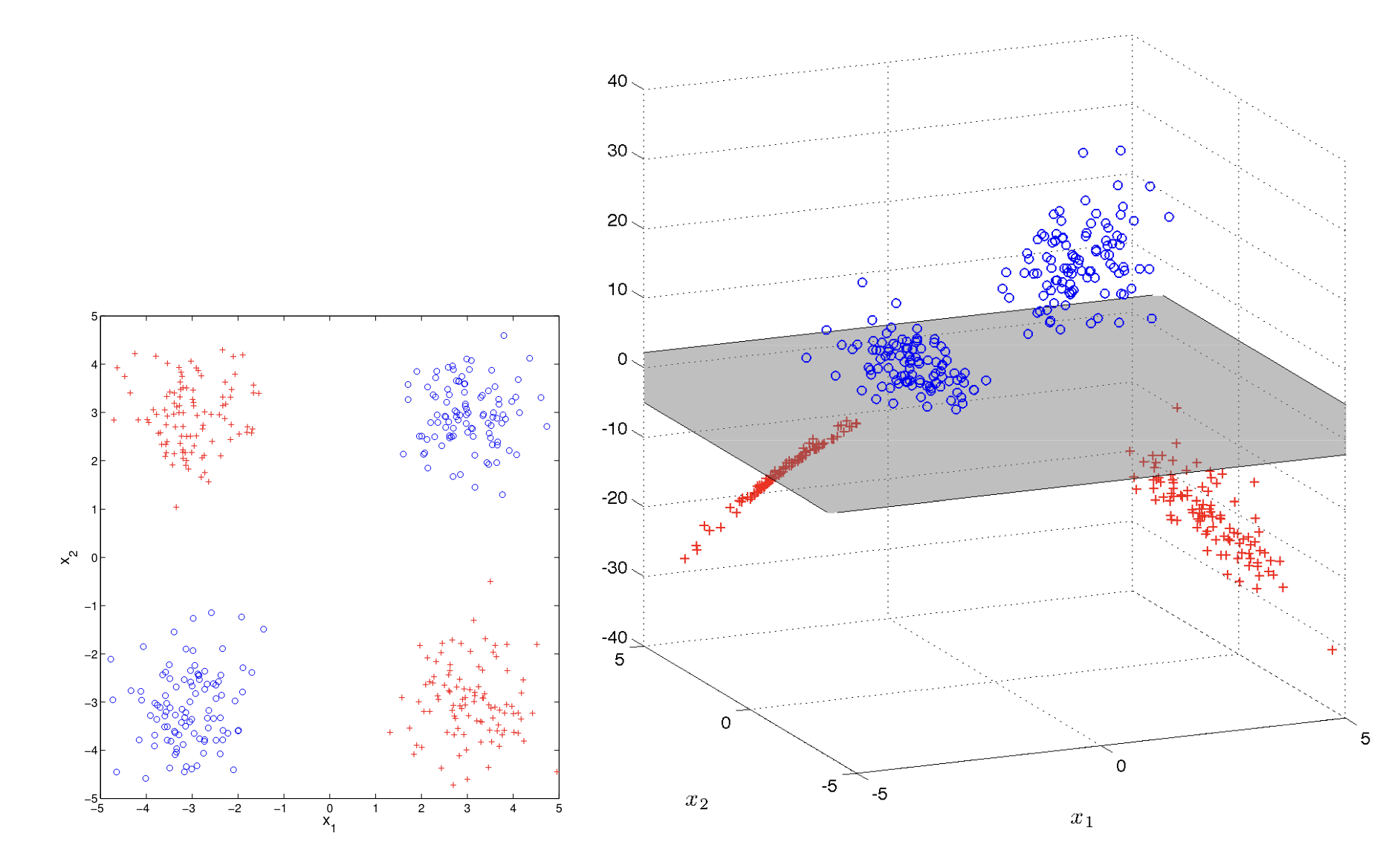
Now, there is no such linear transformation in the same vector space, that will transform our data into a linearly separable format. Instead, we need to increase the dimension of the data set. Consider the XOR Problem in the above. For each point we apply a linear transformation , where . Now, we map each 2D data point into the 3-dimensional space. Notice that the last value of the vector is determines the vertical height of the point, with positive being above the plane and negative being below. Now, we can draw a hyperplane as a decision boundary and once again, our dataset is linearly separable.
In kernel methods, what we are really interested in is the phi () function, which defines the non-linear transformation being applied. We call this feature maps.
Feature Maps
Consider
So we’re looking to transform , most likely to some higher dimension, and we’ve actually already kind of done this when we were concatenating our bias term to the model weight for simplicity in notation. So, we could think of it like: , where is the previous weight before concatenating. Then, in perceptron and also SVM, our classifier was computed via this . This is the exact idea of feature maps. So, given some data, we are going to map and .
-
So, expanding this dot-product in the above, we get:
-
This is the most basic feature map, but this isn’t very expressive as this is a linear transformation of the data points (merely elevating it to in 3-dimensional space).
-
As seen in the very first example, we need a non-linear transformation.
What if we want a more expressive type of classifier? Something like: . What is this? This is another type of feature map called a quadratic classifier. So, for this what are the model weights?
-
is our constant bias, as usual
-
is our vector weight
-
matrix weight with more parameters
-
Why do we use ? This is just a scaling factor, and so does not change the problem by much, we’ll see later on why we choose this scaling factor.
So this is the form of the classifier that is more expressive than the first example. Let’s simplify this, as we want to write this as the inner-product of some sort of feature map and some sort of parameter vector (we want something that resembles . Let’s first expand :
Note that in the above, Now, we can re-arrange this lengthy summation expression. Namely:
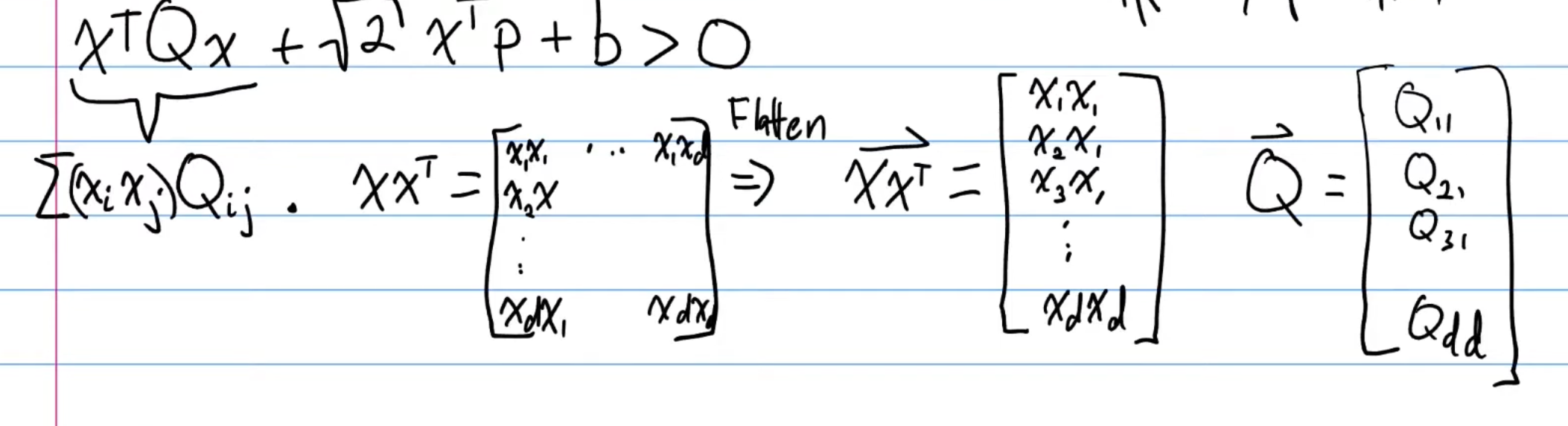
When we flatten, we are stacking the column vectors of the the matrix on top of each other, forming a vector. So, the above summation can be expressed as . Now, we can write the quadratic classifier as the inner product of a feature map and parameter vector:
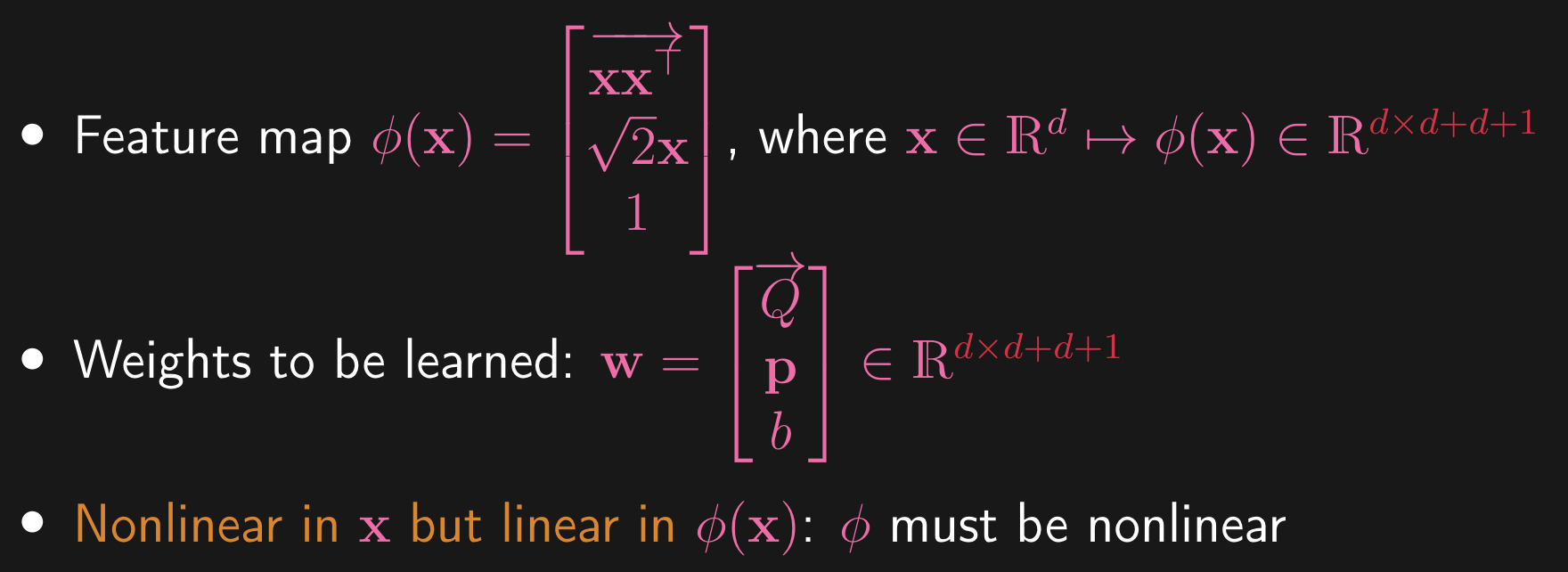
Where again, we’re stacking these vectors vertically to create new higher dimension vectors. So, the quadratic classifier becomes . Now, the feature map blows up the dimension, as we are performing a transformation.
==Computation==
Something interesting to note is the time complexity of such an action, as squaring the dimensionality of data could substantially increase runtime, and thus take much more resources to compute such a model. For example, consider the set of data before the transformation. In that case, computing inner product of weight and data, would be . Now, our weight and data have been exponentially increased in expressiveness. So, if we computed the same thing, the runtime would be , and potentially much much more costly if we had more complex feature map (could easily skew towards , which is often the case when working with real world data). Is this always the case?
-
The good news is, this computation can be done much more efficiently
-
To see this well, let’s revisit the SVM dual problem
Consider:
\begin{array}{ll}
==Notice that in the above, we have now added phi to the data points==. Now, we know:
So, if we compute naively, then we would need time. But, observe:
is the above inner product. We can further simplify this into:
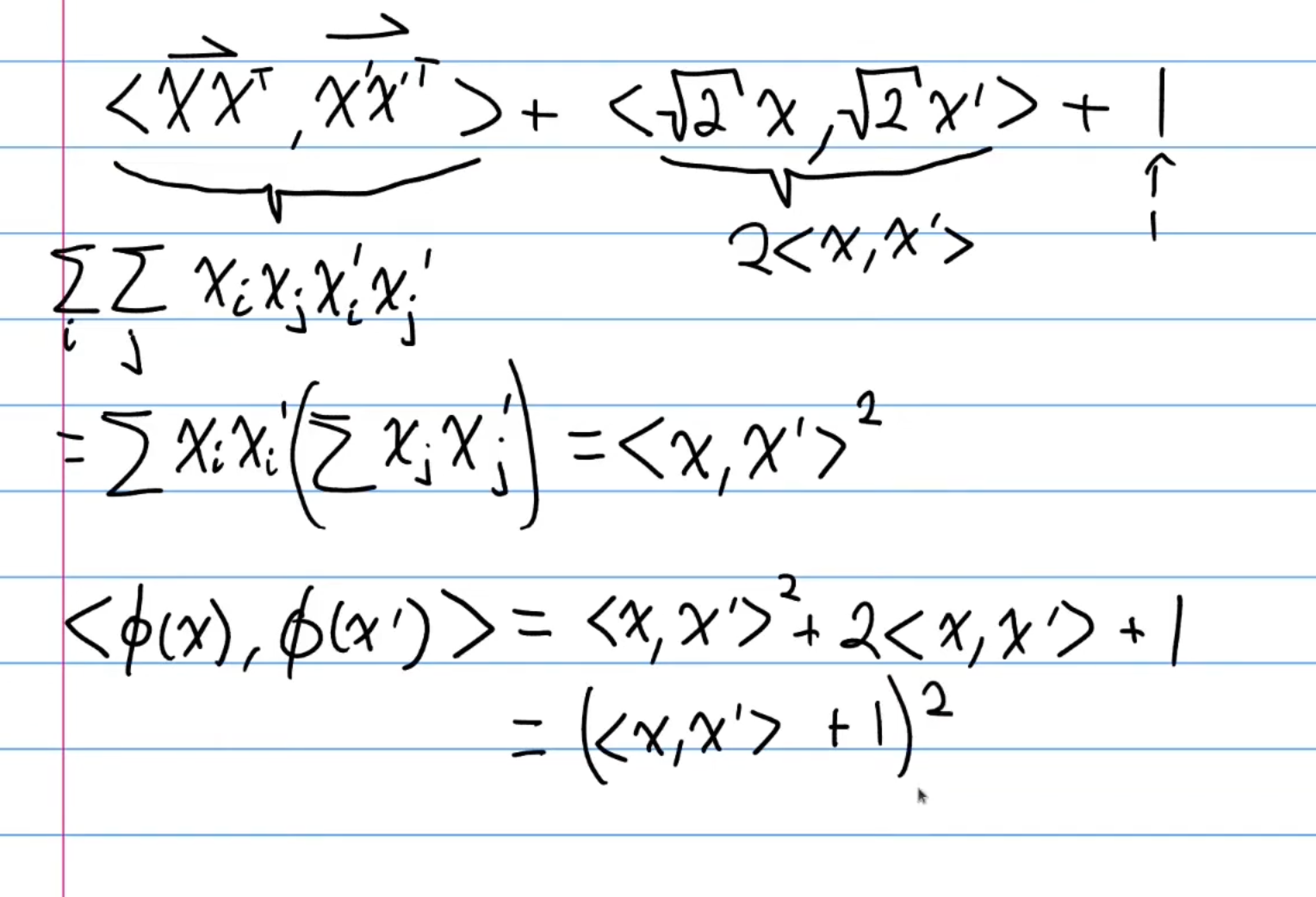
Now why is this useful? As seen, we only need to compute inner product between the 2 data points , and operate in the d-dimensional space instead of space, hence making our computations run in . ==This notion is the idea of a reproducing kernel==, the main focus of this chapter, that is, there exists some function , that computes out feature mapped inner product in dimensional space.
Kernel
We call a kernel if there exists some feature map (some higher dimension, usually) such that , i.e a simple way to represent the inner product of the feature maps of any 2 vectors. This is especially useful in sitations when is incredibly high dimension, and would then take incredible computation time, but is not.
Now, we are familiar with 2D and 3D vector spaces, where operations like inner and outer product are defined. Now, generalizing this to higher dimensions, we call this a Hilbert Space. Think of a Hilbert space as an extension of our usual spaces to infinite dimensions, equipped with tools (like the inner product) to measure lengths and angles, and ensuring that all expected limits are included in the space.
==→ Reproducing Kernel Hilbert Space (RKHS)==
3 main points:
- This is a special kind of Hilbert space (A Hilbert space is a space on which an inner product is defined, along with an additional technical condition) that is associated with a kernel function.
- The space is associated with a kernel function , which is a positive definite function. This kernel function defines the inner product in the RKHS.
- Reproducing property:
-
The reproducing kernel has the property that for any function in the RKHS and any point x in the domain, the value can be computed as
-
But what does this mean? I don’t know lmao. Here’s some stuff that might help:

-
Visual Intuition: Imagine a set of functions living in a space defined by the kernel. Each function can be “probed” at any point by taking an inner product with the kernel function centred at . This probing gives us the value of the function at that point.
-
==→ What makes a valid kernel?==
So, what kind of kernels correspond to feature maps? There are certain properties that are needed to characterize which functions are kernel functions.
Take any set of data points , and let . So, we start with some dataset and we compute the kernel for every pair of points in the dataset, and we store all of these in a matrix. There are some properties we need on this matrix:
-
Symmetric: That is,
-
Positive Semi-definite: Which means we have the following property: for all
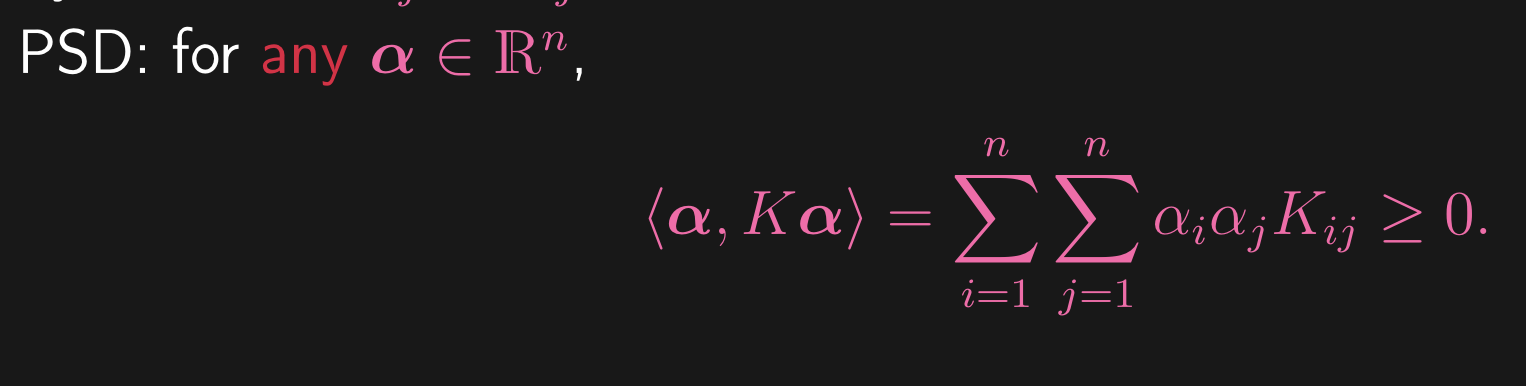
If the 2 properties hold, no matter what data set we feed into it, then it is a valid kernel, where it corresponds to some feature map.
==→ Examples of Kernels==


Using Kernels in SVM
Again we revisit the SVM dual objective function:

This was the derivation we see in SVM lecture. We use it now. So, as seen, we computed the inner product of the 2 data points. Given the matrix we defined above. So, this is effectively:
\begin{array}{ll}
Now, we know that our kernel function. Ok, so with this, we can express our vector weight as:
Now, as we’ve stated before, is too high dimension, and we want to look for better way to do this. This means may be also a too high dimension vector as well. Remember that SVM classifies by:
So, we don’t need to necessarily compute directly, rather, upon expanding, the operation is .
→ Computations for SVM / Tradeoffs
- Linear Kernel: training is over in dataset, and testing is
- General Kernel: training is and testing is
- Why? Well the test set is easy to see. Upon a single inner product between weight and data point, we have: . Now, the kernel component is time as that is the dimension the data point. Then, we sum this over all points in the training set which have , and that is in the worst case where everything is support vector, kernel computations → .
- This is a fairly large cost, but much better than naively trying to compute the the higher dimension inner products in general