This chapter, we introduce the concept of SVM: Support vector machines. This area of machine learning excels in classification tasks. If we think of all our data in some high dimensional space, SVM seeks to find the hyperplane that separates the points of 2 different categories onto opposite sides of the hyperplane. This note will deviate from the course notes, in that, where math heavy is necessary, I will write and explain. But, for areas where it is redundant and easier to explain with words + diagrams, I will make that substitution. Please still review course slides in addition to this, thought once you have reviewed this, course slides should only be ~10 minutes of reading, and mostly review. The diagrams are sources from this video:
Support Vector Machines: All you need to know!
MachineLearningDeeplearningSVM
https://www.youtube.com/watch?v=ny1iZ5A8ilA&ab_channel=IntuitiveMachineLearning
Overview
SVM are a form of non-linear supervised machine learning models, where given some labeled training data, SVM will help help us to find optimal hyperplanes which categorize new examples. Let’s see an overview on how to find this optimal hyperplane. Consider the following sets of data:
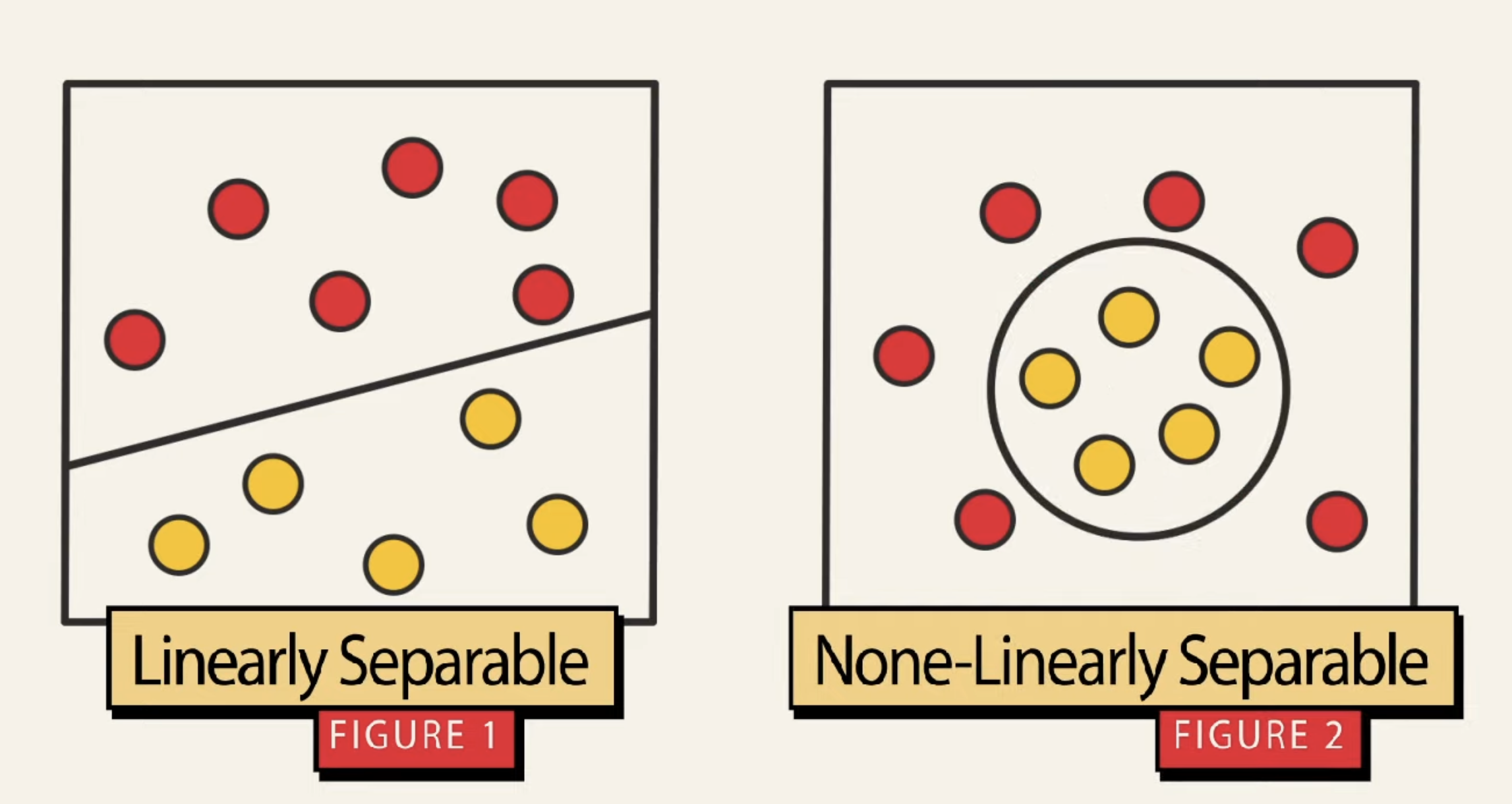
Let’s have a close look at figure 1. Amongst that data, there are multiple hyperplanes that can be drawn to separate the 2 classes of data. Which one is the best? SVM helps us choose the best hyperplane by maximizing the margin: the margin is the distance between the hyperplane and the nearest data point from either class. By maximizing this margin
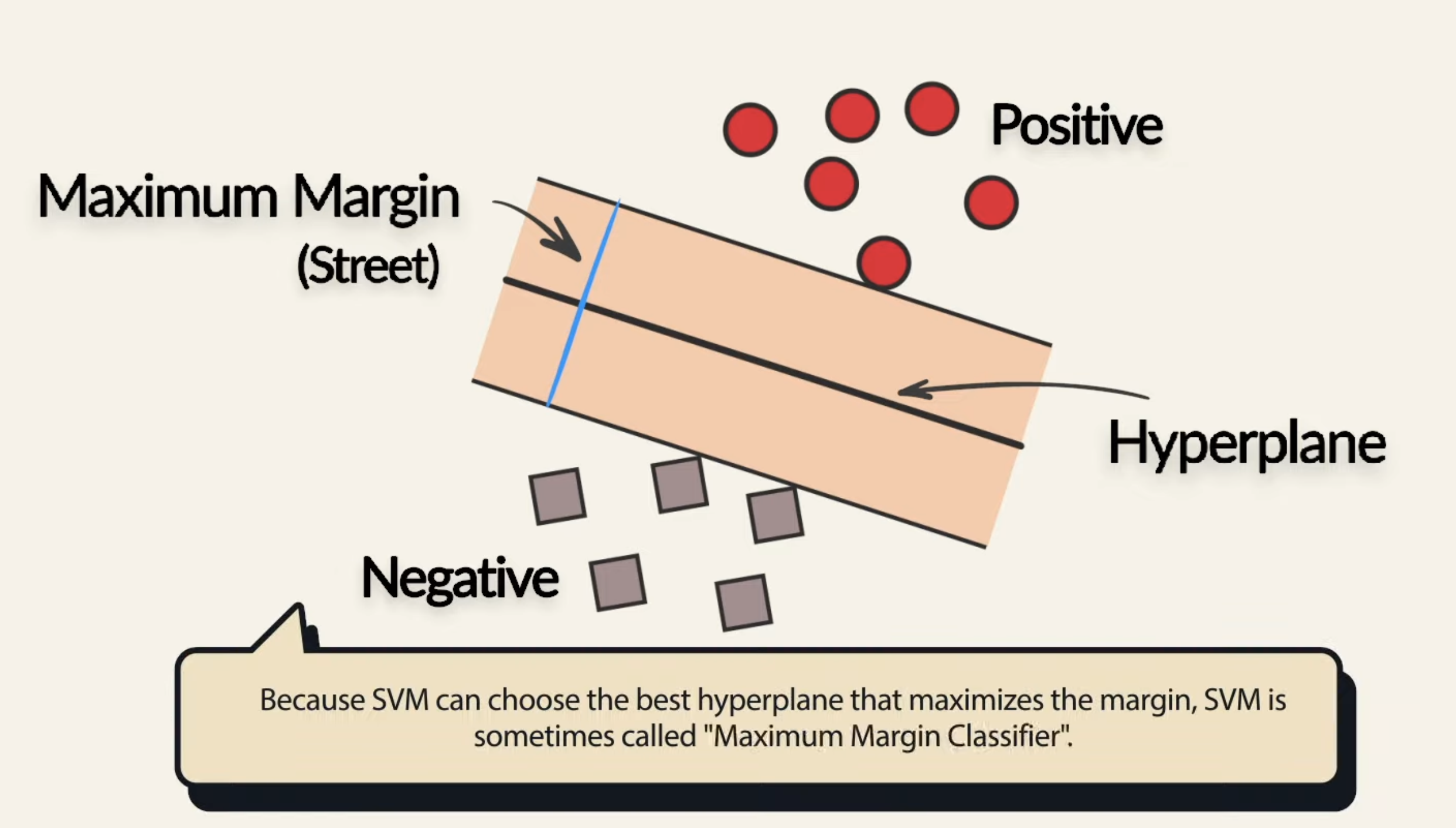
Now let’s introduce another concept: Support Vectors. These are the data points that lie closest to the hyperplane, and thus the most “difficult” to classify. Unlike other models such as regression or neural networks (where every data point influence the final optimization), for SVM, only the difficult points, the support vectors, have an impact on the final decision boundary. So, moving the support vectors alters the hyperplane, but moving data points that are not the support vectors, does nothing.
In essence, the concept of SVM is very similar to perceptron, where we are given a set of input data and in order to predict the corresponding labels , we multiply our data by a weight and add a bias: . So, from this, you might wonder “this is just like a basic dense layer in a neural network, whats the difference then?”. However, there is a major difference, in that, SVM will optimize the weights in such a way, that only the support vectors determine the weights and decision boundary. Let’s go through a high-level look at the mathematics:
Mathematics Overview
Consider the following diagram:
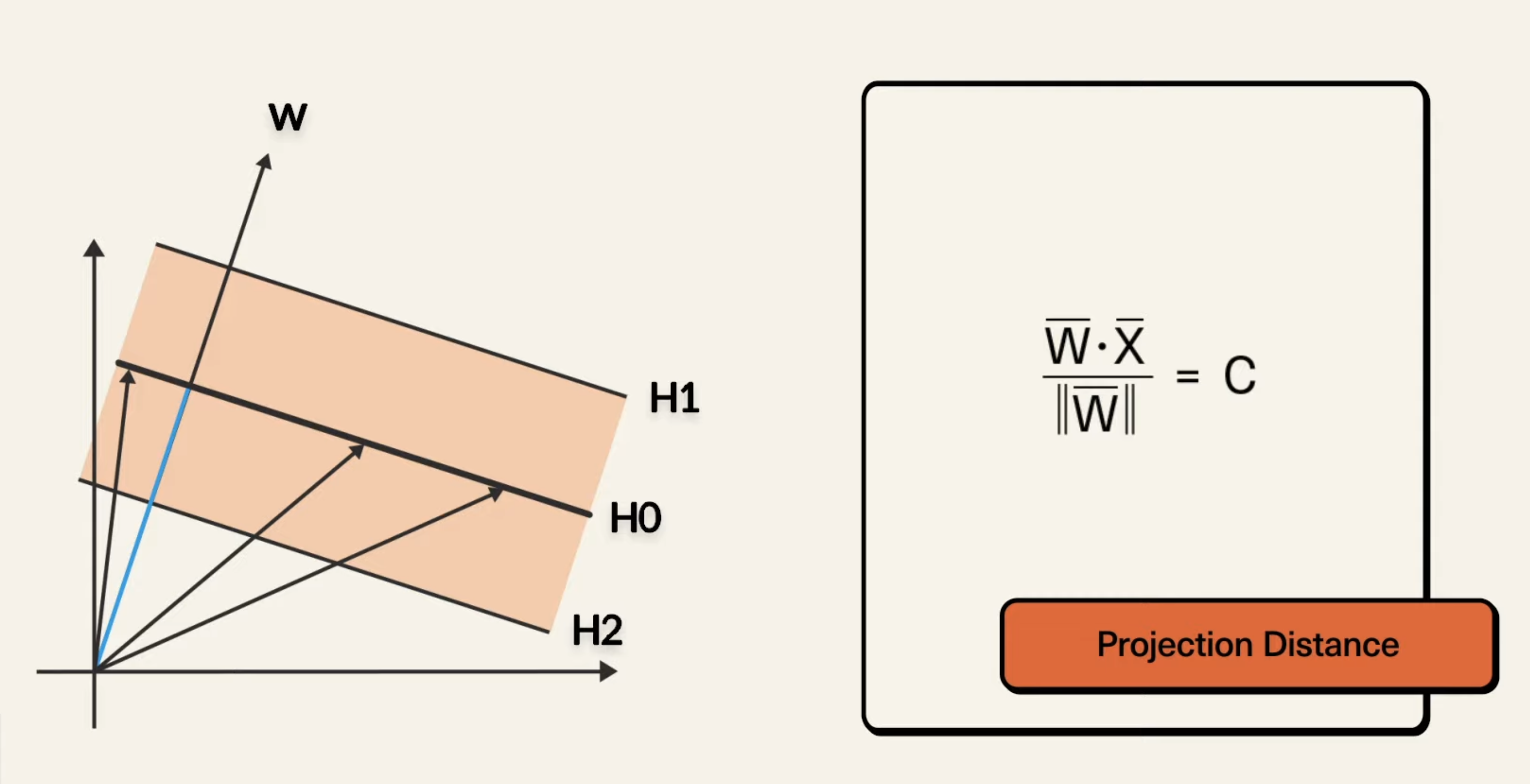
Then, multiplying both sides, we can obtain , and then we can substitute the right side with , so it becomes , so, . This is the equation of the hyperplane in the above. This formula is for the 1D hyperplane (recall in an n-dimensional space, a hyperplane is an (n-1)-dimensional subspace). If we wanted to generalize the above hyperplane equation to 2D, we would have something like: , and so on.
So, we have are our hyperplane, which provides us with basic binary classification capabilities, where if we have , then we predict the point as a “positive” sample, and “negative” if . Now, since we have equation for the hyperplane, we can easily find the equations for and above, being respectively and . To make things easier, we can scale the dataset so that we have and . To show a way to express the margin, we introduce 2 vectors:
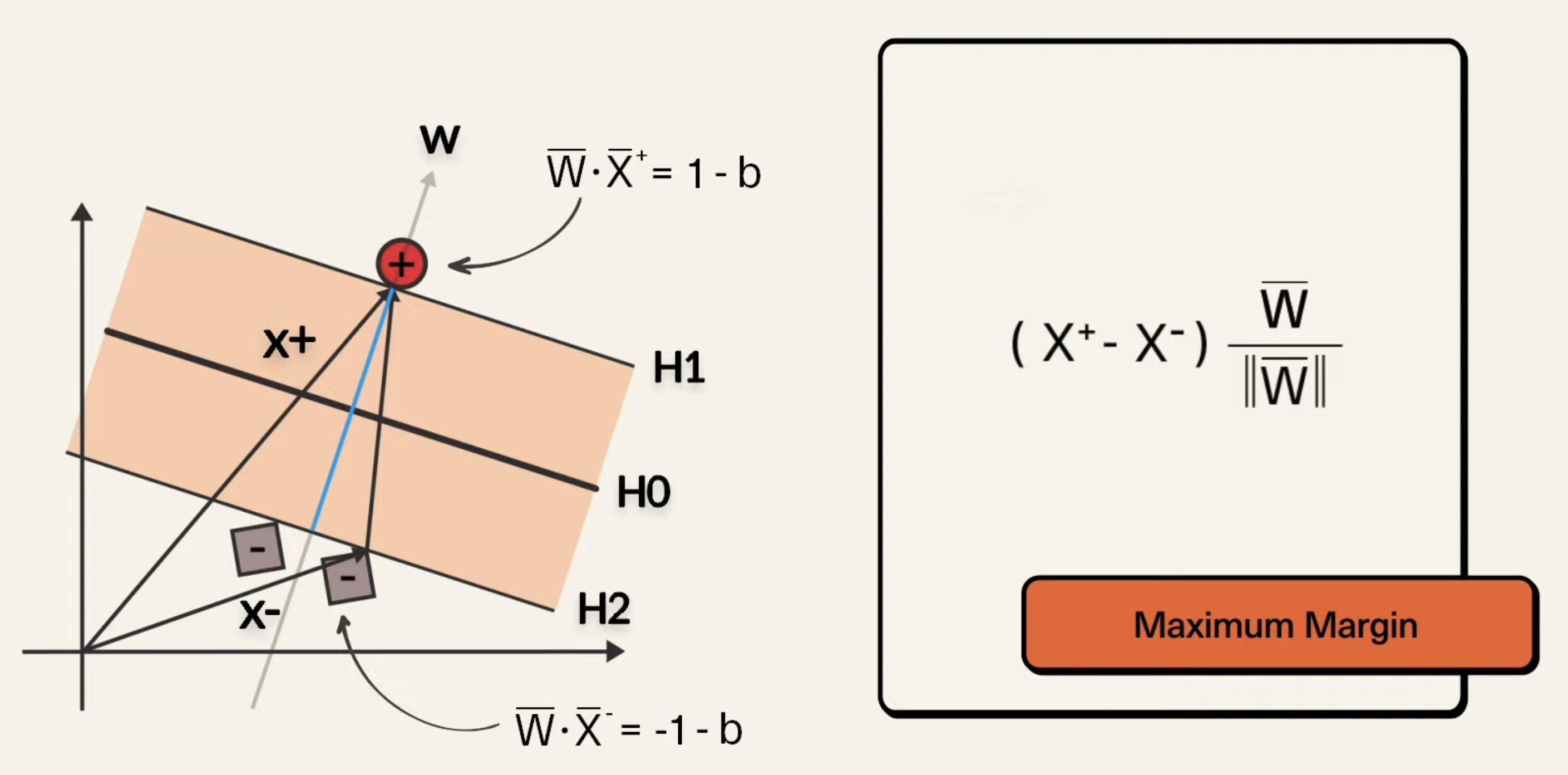
What the above shows is this:
- We have our vectors that point to a positive and negative point respectively
- Then, we take the difference of the 2 vectors (which is the black vector on the right of the blue line) and dot product it with unit vector perpendicular to , and we can get an expression for the width of the margin. The equations for and follow the derivation above. So, in the above image, that expression can be simplified by multiplying the numerators, and then substituting the equations for in, which ultimately becomes: . This value is the simplified margin width, so, to maximize the width, we need to minimize the magnitude of . For mathematical equivalence, it is the same to minimize . But, we cannot keep increasing this width, we have a constraint (max something with constraint, …, CO lol). We have the constraint that no points will be inside of the margin, and so, we have:
-
For all positive points:
-
For all negative points:
-
Now, the above can be simplified into one equation, and greatly resembles what we were doing in perceptron:
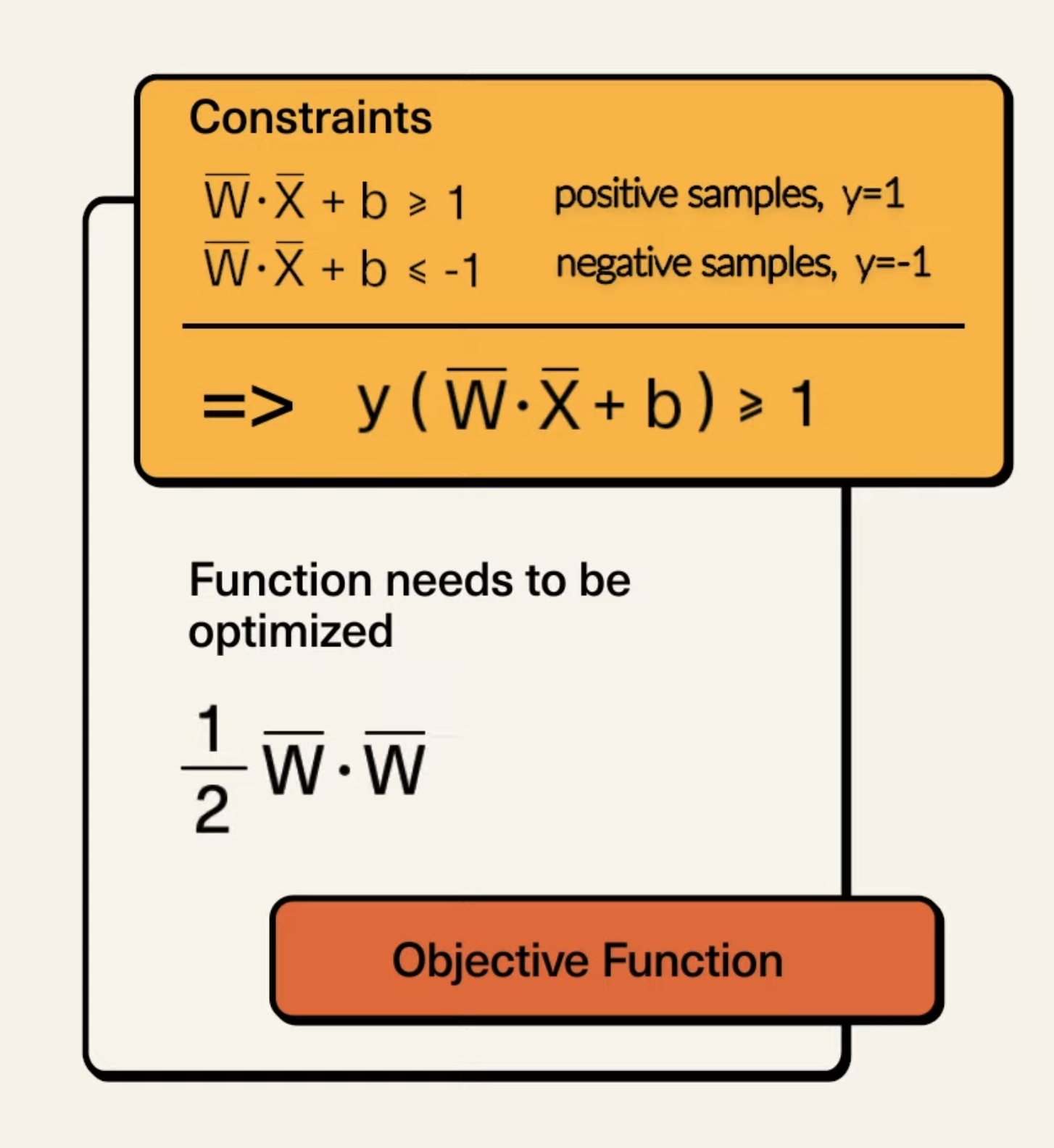
So, the above minimization problem of SVM is our Primal, which we can rewrite more clearly:
\begin{array}{ll}
Where:
-
is the weight vector
-
is the bias term
-
is the i-th training sample
-
is the class label of the i-th training sample (either +1 or -1).
We solve this with Lagrange multipliers, and more specifically, Lagrangian Dual. So, we need to find the dual problem first, which we use Lagrange multipliers for. We introduce a Lagrangian multipliers for each constraint. This gives us the function: . To find the dual, we take partial derivatives of with respect to and , and set them to 0. Why is this? Recall that when we looked at Lagrange multipliers, we saw:
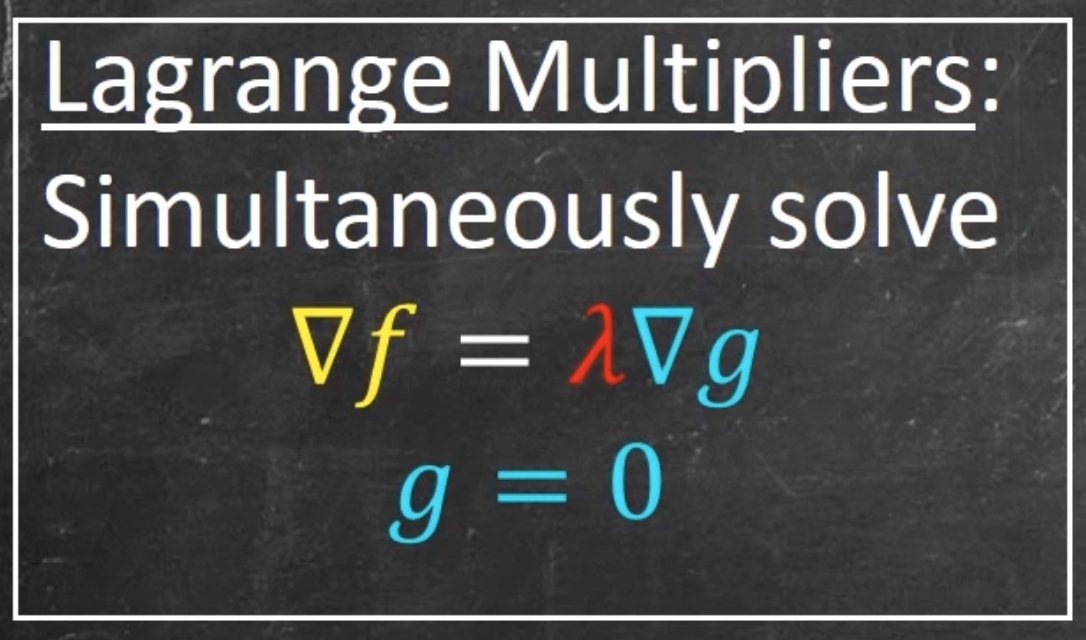
Where f is obj func and g is constraint
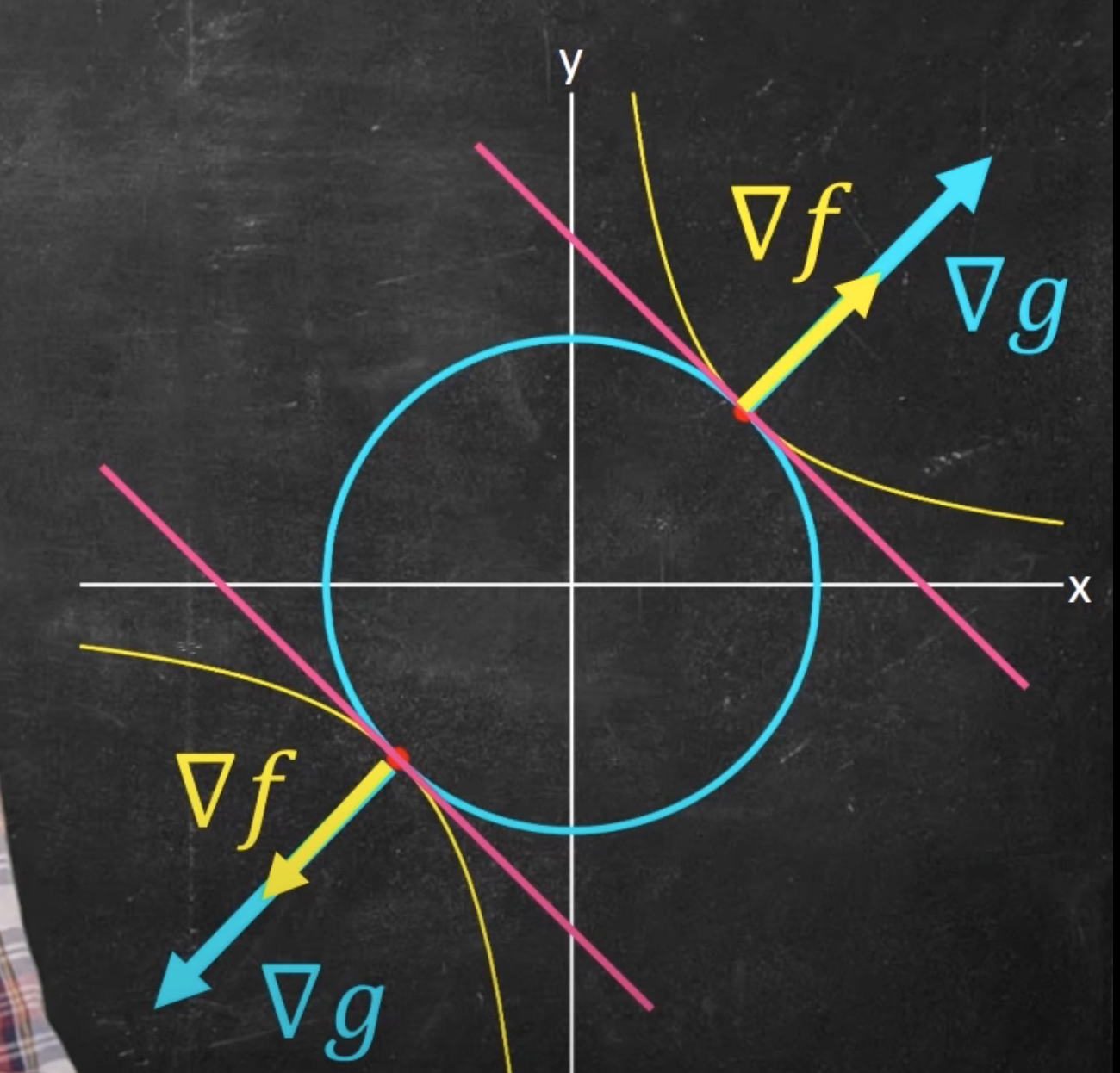
So, we take gradient (hence why are taking partial derivatives in the above). Taking the partial derivatives with respect to , we get:
Same for :
Substituting back into the function , we get the dual problem (this is in course notes, too, so no need to re-write later on):
\begin{array}{ll}
In hindsight, a lot of the dot products above weren’t written with
<>__, just keep that in mind, same thing though
Now, we can easily multiply objective function to make this a min problem (as is in the course slides). The dual problem is often easier to solve and provides the same solution as the original optimization problem. Once you solve the dual problem, you’ll get the optimal values for the Lagrange multipliers . The support vectors are the data points for which . These are the points that lie on the margin. Then, we compute the hyperplane via weight normal vector . Also, with the above derivation, we can re-write the equation of the hyperplane and alter the decision boundary rule:

Then, to find bias, we take any support vector , and compute: , and for stability, we may often choose to take the average over all support vectors. Now that we have weight and bias, we have model for classification.
This has all been hard-margin SVM, and we are operating under the pretence that the data is linearly separable. In cases where the data is not linearly separable, we would use soft-margin SVM, which we will detail in the below. Next, we will look at another technique to combat data that is not linearly separable, but that we want to use SVM for classification, called kernel trick.
Soft-margin SVM
So, in the above hard-margin examples, we’ve operated under the assumption that the data points were linearly separable with not outliers. When if there is some noise and outliers in the dataset? For example, what if we had something like:
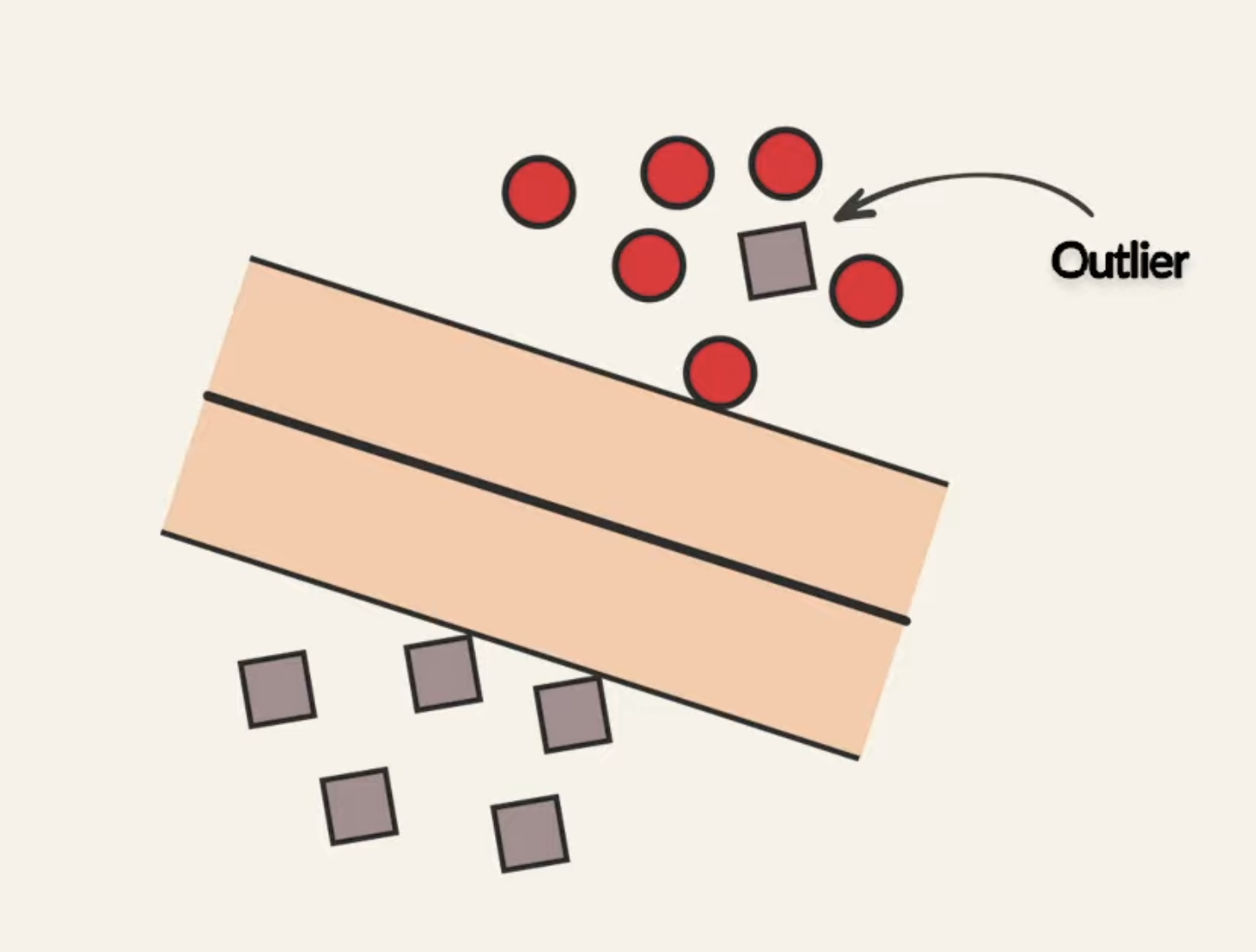
For something like this, hard-margin SVM would fail to find the optimization for the hyperplane. In hard-margin, in order for a data point to be classified as positive, we need it satisfy the condition: . We now address this limitation with soft-margin SVM. First, let’s add a slack variable to the right hand side of that inequality, providing us with:
Without slack variables, the SVM would be forced to find a hyperplane that perfectly separates the data, which may not exist. The slack variables allow for some miss-classification, and helps the model to find a balance between margin width and classification accuracy. The introduction of slack variables provides a way to control the trade-off between maximizing the margin and minimizing the classification error. This is done through the regularization parameter in the objective function → this is L1 Regularization, adding some kind of penalty for large values of . The regularized objective function becomes:
We note that , so always positive, and the regularization parameter determines how important should be, which intuitively represents how much we want to avoid misclassifying each training example.
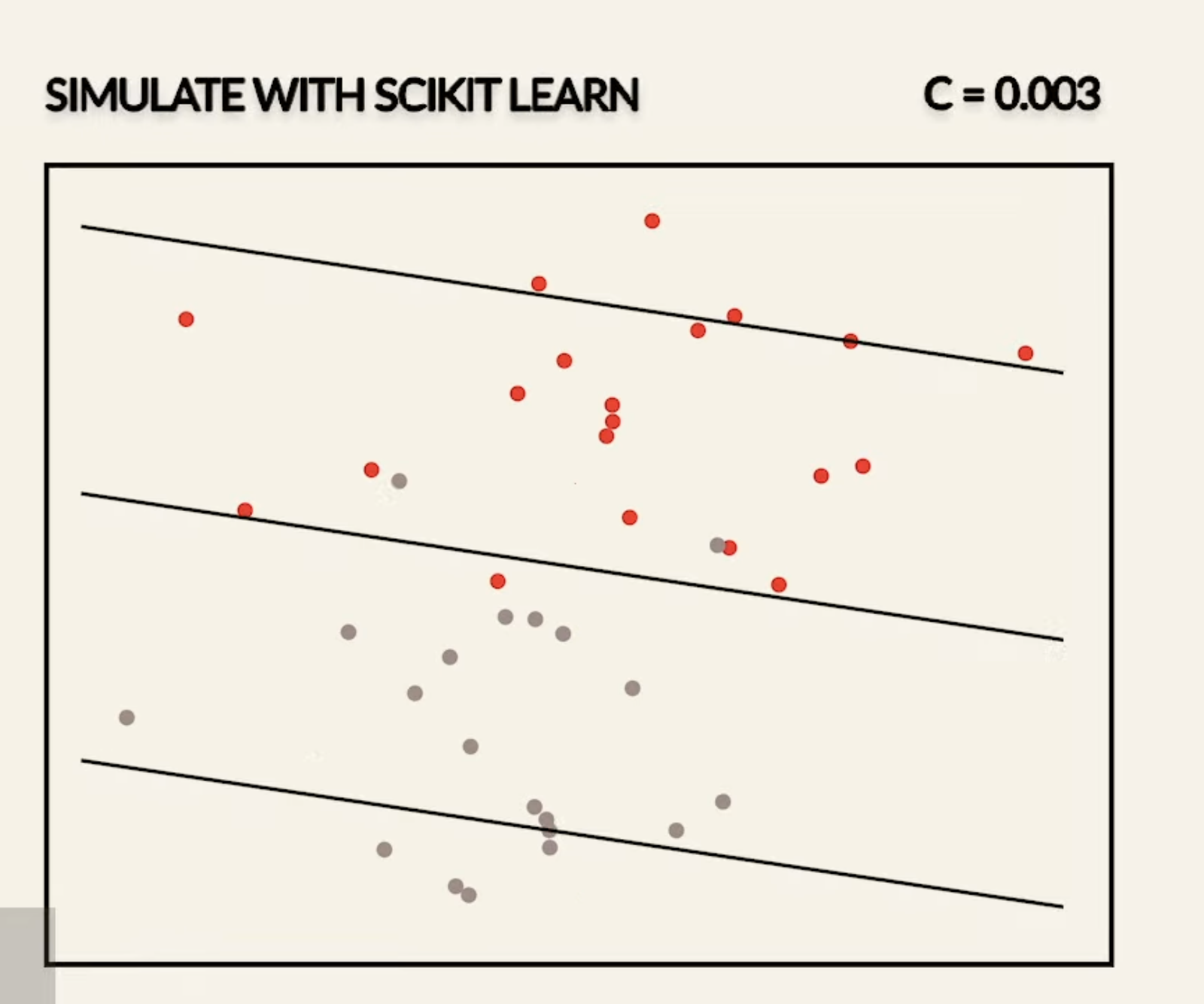
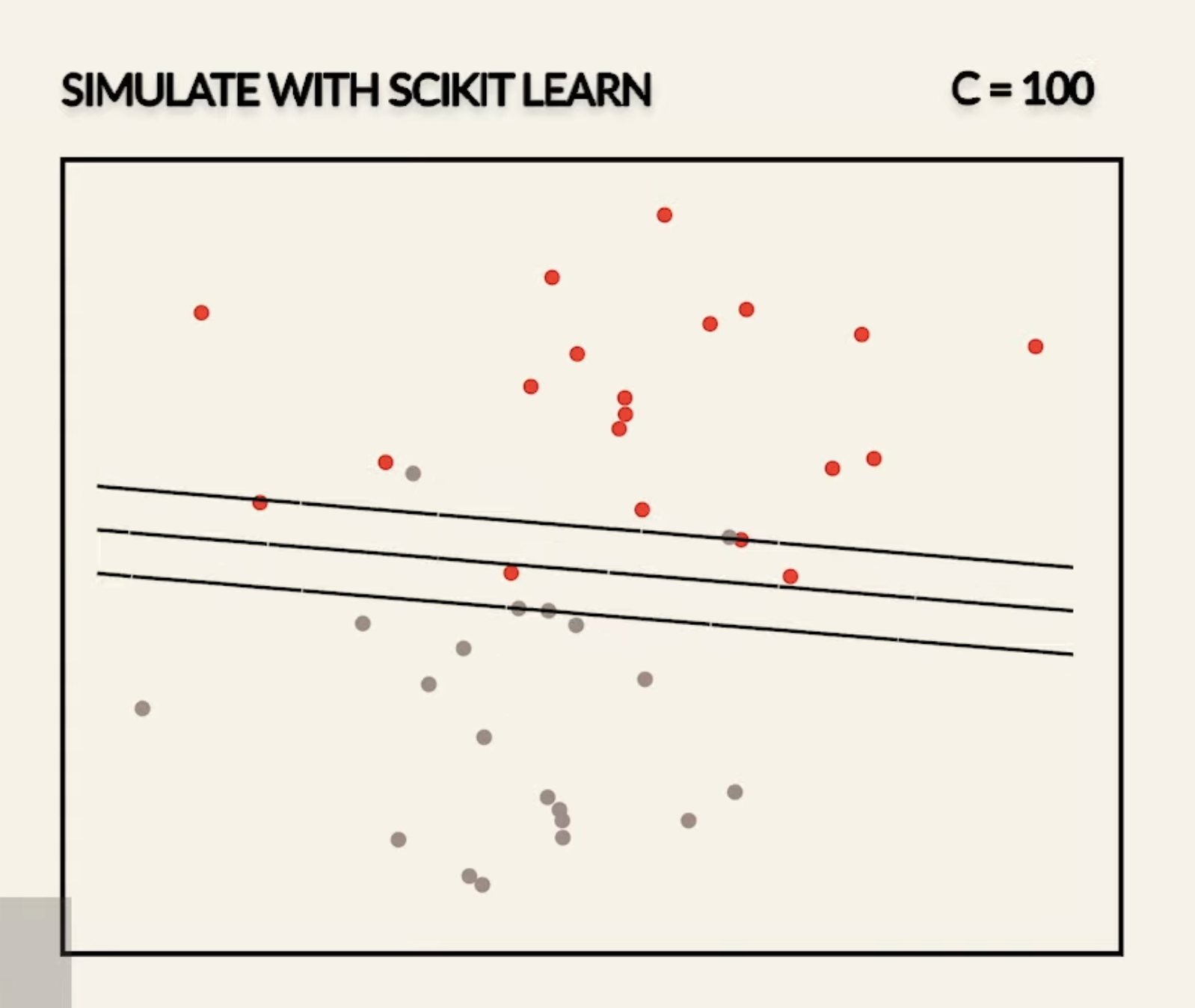
- Smaller emphasizes the importance of and a larger diminishes the importance of
- In fact, if we set to be , we will get the same results as hard-margin SVM
So, smaller values of will result in wider margins at the cost of some misclassifications, and large values of will result in smaller margins, and less tolerant to outliers.
But this, is only for instances where there is some noise or outliers in the data, and otherwise, would have been separable. What if the non-linearly separable data is not caused by noise? What if the data are characteristically non linearly separable? For this, we can use the kernel trick
Now, in the lecture notes, instead of using this slack variable, we directly used hinge loss. Mathematically, the two approaches are equivalent in that they both aim to find the optimal hyperplane that maximizes the margin while allowing for some classification errors. The differences lie in how these errors are quantified and handled in the optimization problem. Hinge loss can be viewed as a streamlined or implicit way of incorporating the idea of slack variables. Rather than introducing as separate variables, hinge loss directly measures and penalizes the violations of the margin constraints. In essence, we are defining the zeta to be the value of hinge loss, described below:
→ Hinge Loss
Hinge loss is a crucial concept in SVM, particularly in the context of classification problems. Hinge loss is used to measure the error of a classifier, specifically in the context of SVMs. It is designed to ensure that not only do we classify data points correctly, but we also classify them with a sufficient margin. The hinge loss function is defined as follows:
-
For a single data point , we get:
-
where is the model, or in longer terms:
So, how do we understand Hinge Loss:
-
Correct Classification with Margin: If a data point is correctly classified and lies outside the margin (i.e., ), the hinge loss is zero. This indicates the classifier is not penalized for this data point and is correctly classified with sufficient margin
-
Incorrect Classification with Margin: If a data point is either misclassified or within the margin (i.e. ), the hinge loss is positive. The amount of loss increases as the prediction deviates from the desired margin, penalizing the classifier for errors and margin violations.
The objective of training an SVM is to find the parameters and that minimize a combination of hinge loss and regularization term. This can be formulated as:
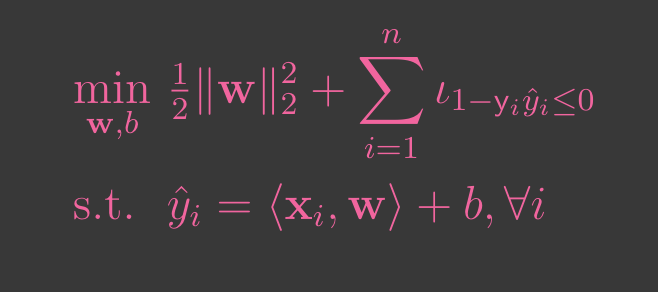
Hard-Margin SVM
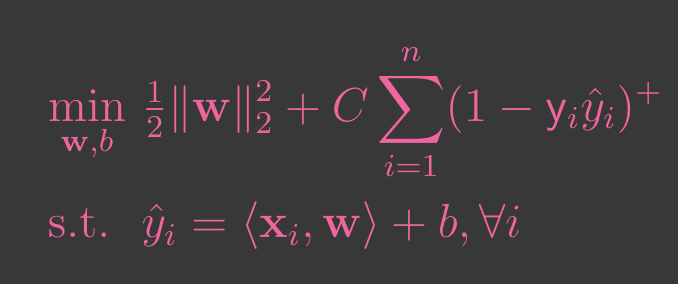
Soft-Margin SVM
is the regularization term that helps in maximizing the margin by penalizing large weights.
Let’s take a brief look at the Kernel trick, which we will deep dive into in the next chapter. This is especially important in situations when our dataset is non-linearly separable data. Consider something like:
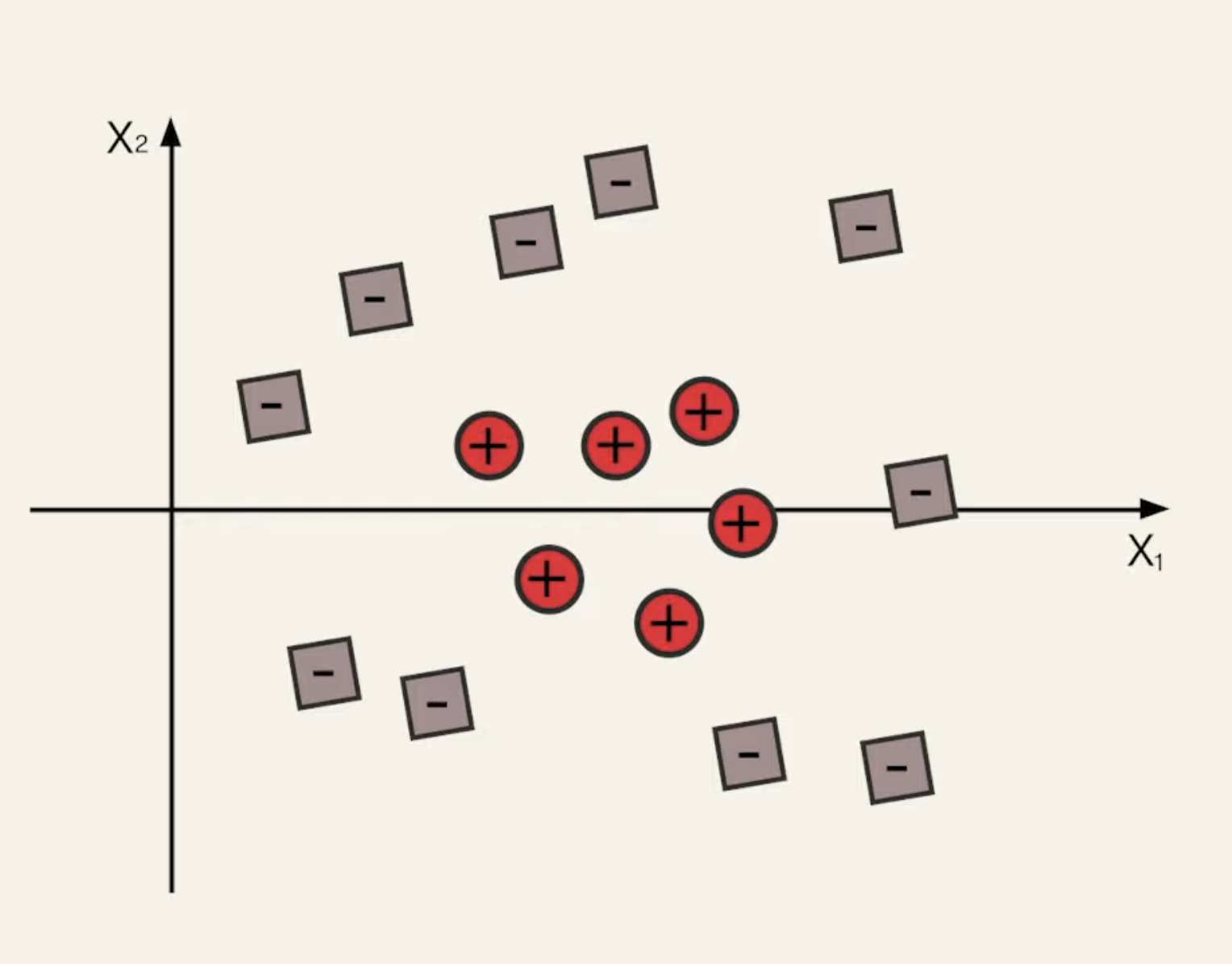
If we lift this, then we can fit some higher-dimension hyperplane. Now, let’s revisit our Lagrange Equation:
We can scale this to become our Kernel Function:
That is, the trick is to replace our dot product with a newly defined kernel function . This a small but powerful trick. For the above graph, we coan define
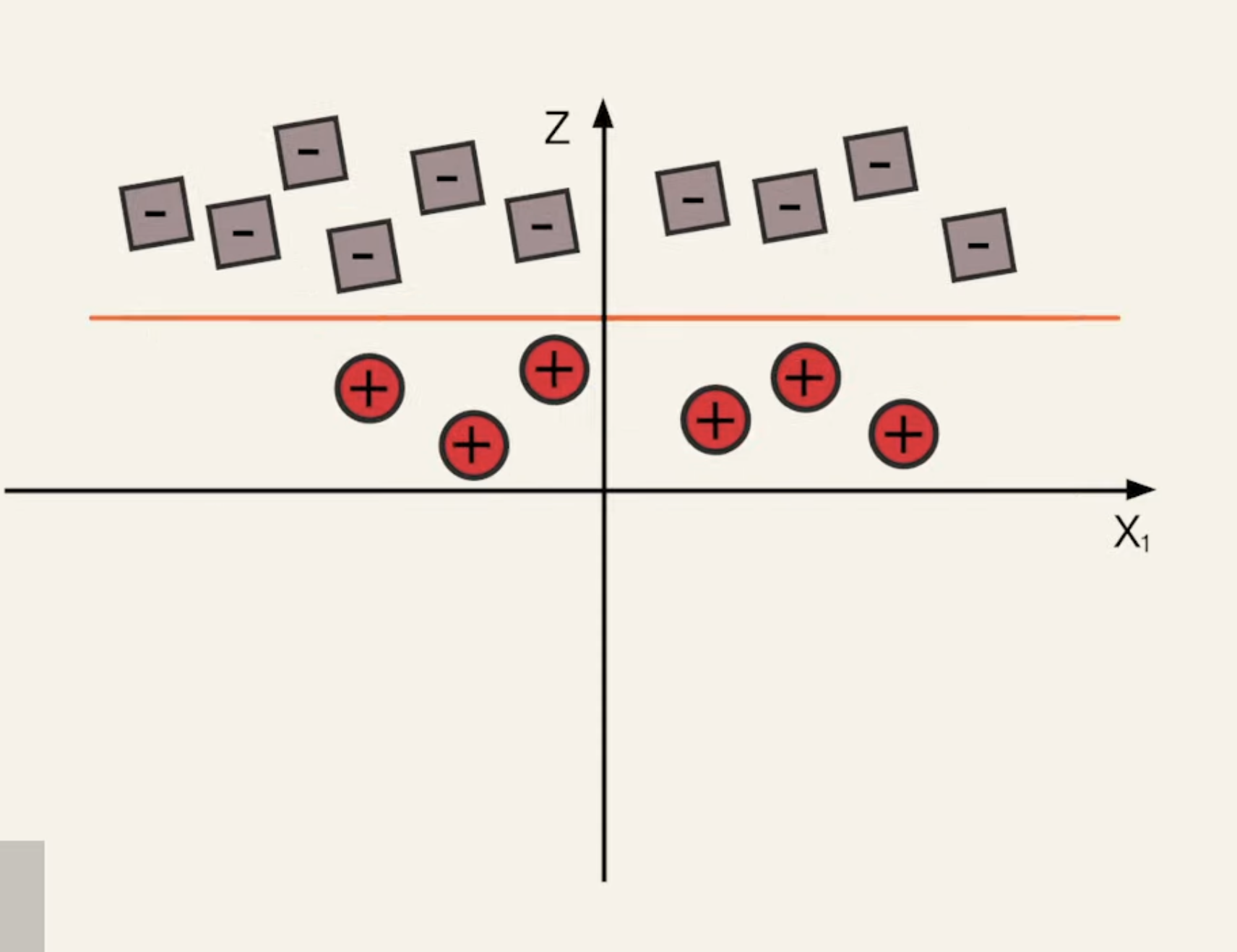
Notice that this is z dimension, so we’ve transformed our data into 3D space, and now, we can see a hyperplane.