Directories map human friendly names to i-numbers. In this lecture, we go more into directories in file systems. Before we start, let’s quickly go over the differences between a directory **Inode** and a file **Inode**. We’ve seen what the file Inode is like in the previous lecture, here what a directory one looks like:
- First every
Inodespecifies whether it is a directoryInodeor a file one - Directory
Inodescontain entries that map filenames to theInodesof the corresponding files and directories
This will be slightly tweaked in the future, but this is pretty much it.
- In most UNIX-Style file systems, the root directory is always
Inode2 - Some special names include:
- Root:
/ - Current directory:
. - Parent directory:
..→ why we docd ..→ tocdback to parent directory
- Root:
- Using given names, we only need 2 operations to navigate the entire name space:
-
cd name: move in directoryname -
ls: show files in current directory
-
→ Quick example: **/a/b/c.c**
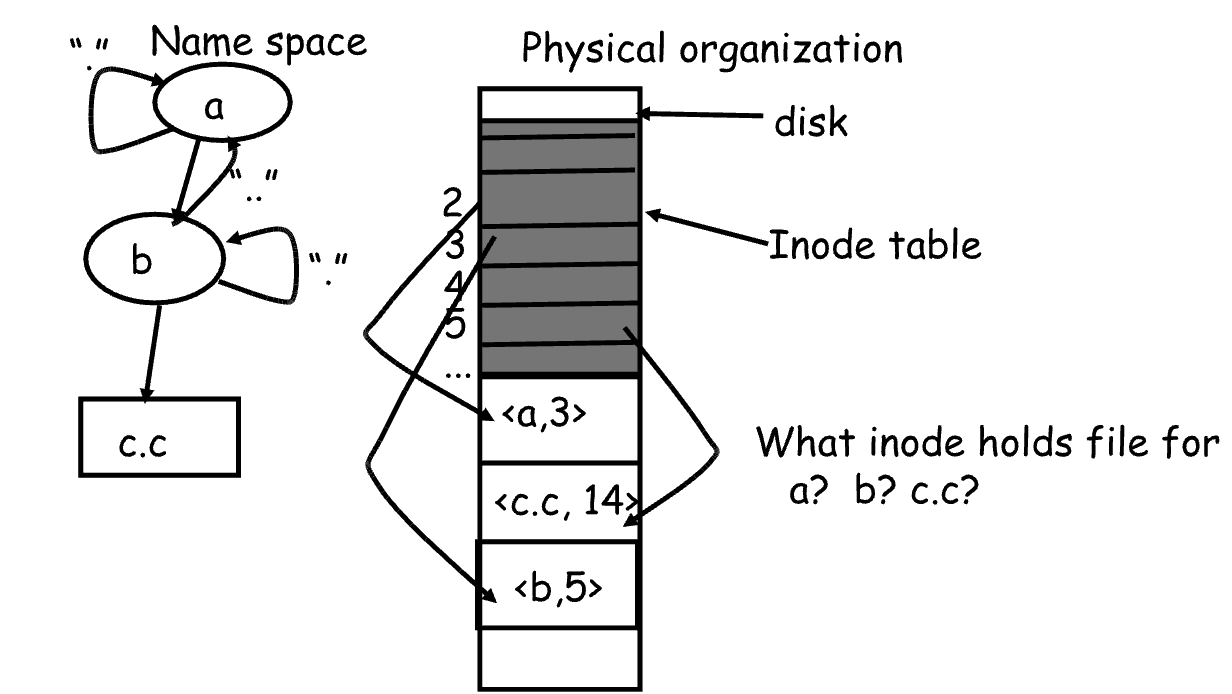
The graph should be fairly intuitive. For example, if you have a directory named **a** and inside it a file **b**, the directory **a** will have entries for **.** (pointing to the Inode of **a**) and **..** (pointing to the Inode of the parent directory). The file **b** will have its own separate Inode.
- Both Linux and Unix store a count of pointers, called hard links, to an
Inode→ we can create synonyms for names- So multiple filenames reference the same
Inode - Creating a hard link, say I do
ln f1, f2. This means now whenever I interact with filef2, it will actually bef1, asf2“points” to theInodeoff1→f2does NOT HAVE ITS OWN NEW**INODE**
- So multiple filenames reference the same
- Soft Links (symbolic links) are synonyms for names:
- It points to a file (or directory) name, but the original file can be deleted from underneath it, or have never existed in the first place
- A softlink is file, with its own
Inode, that contains a path variable. So, if I didln -s f1 f2, thenf2would be a new file with its ownInodethat contains the path to the directoryf1is in - They are implemented like dictionaries: the
Inodehas a symlink bit set, and its file contents are the name of link target
- In both, f1 and f2 can be any path variable.
Case Study: Speeding up FS
The original Unix FS was simple and elegant:

-
Components:
- Superblock (specifies information about the file system → # of blocks in FS, max # of files, pointer to head of list of free data blocks)
**Inodes**→ contain the meta information on the files- Hard Links → as mentioned above
-
The problem is → this is slow (reasons for why are at end of the previous lecture)
In this simple implementation, there are many performance costs:
-
Blocks too small (512 bytes) → this size is alright for small files, but often times, files are larger.
-
Poor clustering of related objects → saw this last lecture as well
The FSS (Fast File System) fixes these issues (to a degree)
In the above, we mentioned that the block size being small was a performance cost. So, why not just make the blocks bigger? As we know by now, while this certainly increases bandwidth (read or write more in one file system access), this can introduce internal fragmentation. The solution for this is fragments
→ Fragments
In the BSD Fast File System:
- There are larger block sizes (4096 or 8192 bytes)
- It allows larger blocks to be chopped into smaller ones, called fragments
- Used for little files and pieces at the ends of files
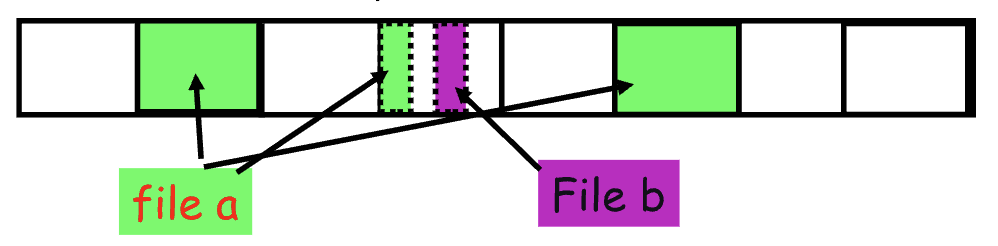
- What is the best way to eliminate internal fragmentation?
-
Of course variable sized splits would be ideal, but for simplicity, FFS uses fixed-size fragments (1024, 2048 bytes) → so they can be easily recombined or reused
-
→ Clustering related objects in FFS
The second performance cost we mentioned, was that there was poor clustering of related objects in the disk. We now see how FFS improves upon this.
- We introduce the idea of cylinder groups, and how we group 1 or more consecutive cylinders into a “cylinder group”
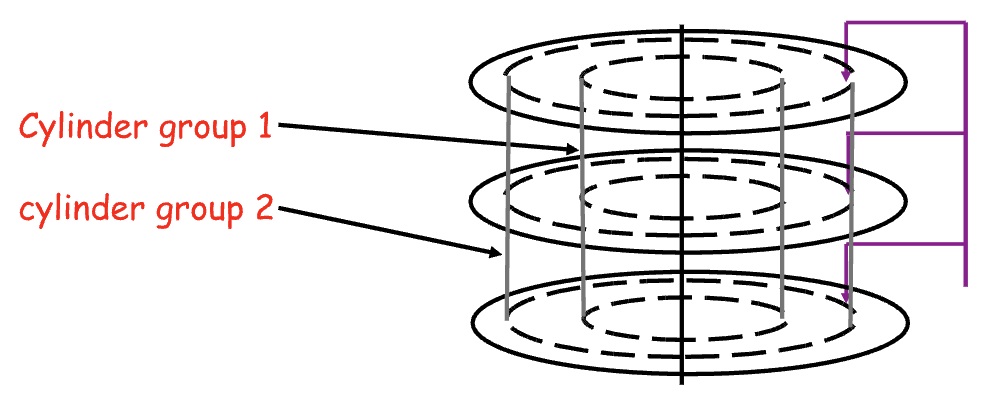
-
Key idea: the system can access any block in a cylinder without performing a seek (the needle is already in that general area on the top of the circle) → the next fastest place is an adjacent cylinder
-
FFS tries to put everything related in the same cylinder group
-
FFS tries to put sequential blocks in adjacent sectors because sequential access is common
-
FFS Tries to keep the
**Inode**and the file data together in same cylinder because if you look at theInode, most likely you will look at the data too -
FFS tries to keep all
**Inodes**in a directory together in the same cylinder → if you access one, may want to access the others
→ What does disk layout look like
Essentially, each cylinder group is basically a mini-Unix file system:
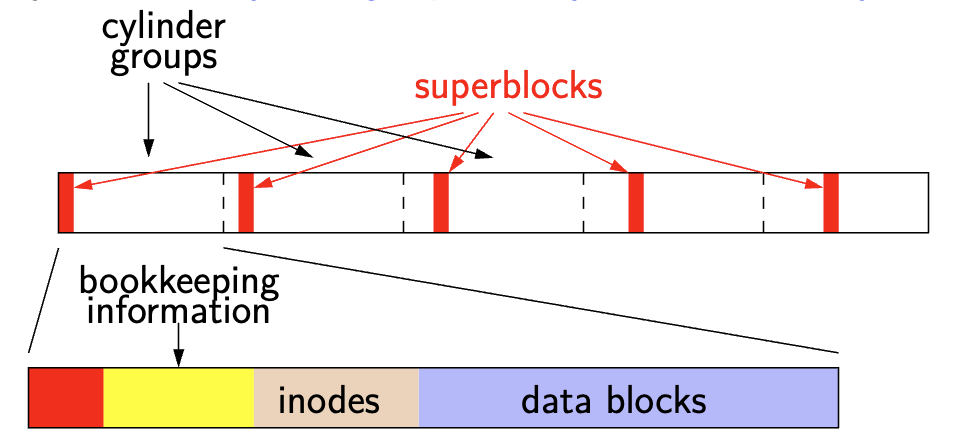
-
Each cylinder group has its own super block,
Inodes, etc. How to ensure there is enough space for relating things?- Place different directories in different cylinders
- Keep a “free space reserve: so can allocate near existing things
- When file grows too big (1MB) → send its remainder to other cylinder groups
- small files tend to be collocated with their directory
- large files get load balanced across all cylinder groups
-
This gives us a nice way of spreading data across the disk, when we change directories or when we access very large files where we are willing to pay the penalty of a seek. But this gives good locality for small files and their
Inodeswithin the same directory → in one cylinder
→ Re-Visiting Free Block Linked List
-
In the old Unix FS, a linked list of free data blocks was maintained. If we needed another data block, we would remove the head → very easy implementation. The problem is, as we start to release and re-allocate blocks, this linked list becomes messy and jumbled all over the place. This makes finding adjacent blocks hard and slow

-
FFS → switch to a bit-map of free blocks
-
1010101111111000001111111000101100
-
Easier to find contiguous blocks → small enough to be stored in memory, each binary digit represents if a block is free or not
-
Time to find free block increases if there are fewer free blocks
-
→ Using a bitmap
- Remember the bitmap is very small, and we can keep the entire thing in memory. Say we have a 4GB disk and 4KB blocks. Then:
- Our bit-map’s size would be: KB
- Can efficiently allocate blocks close to another block, say in the file
- Check for blocks near
bmap[x/32]→ we divide by 32 since usually, within 32 is a healthy distance - If the disk is almost empty, will likely find one near by
- As disk becomes full, search becomes more expensive and less effective
- Check for blocks near
- Trade space for time → specifically, search time and file access time
- Reduces the time required to search for free blocks, most of the time, but now we do need to store it in memory
- To mitigate the challenges as the disk becomes full, a reserve of free space (e.g 10%) is kept
-
Don’t tell users
-
Only root user can allocate blocks once FD is 90% full
-
With 10% free, can almost always find one of them free
-
→ Gains
So, what did we gain?
-
Performance improvements:
- Larger bandwidth than original Unix system
- Better small file performance (close to
Inodeand related data now)
-
Is this the best we can do? No.
Now that we have looked at cylinder groups, let’s make some brief comments on the parts of one:
-
Superblock
- Entire system has a super block
- Contains file system’s parameters
- disk characteristics, block size, Cylinder Group (CG) info
- Information necessary to locate an
Inodegiven its i-number
- Replicated once per cylinder group
- Also contains non-replicated “summary information”
-
blocks, fragments,
Inodes, directories in the ENTIRE FS
-
-
Bookkeeping Information
- Block bit-map → bit-map of available fragments → use for allocating new blocks/fragments
- Summary info within each cylinder group → use when picking cylinder group from which to allocate
-
**Inodes**and data blocks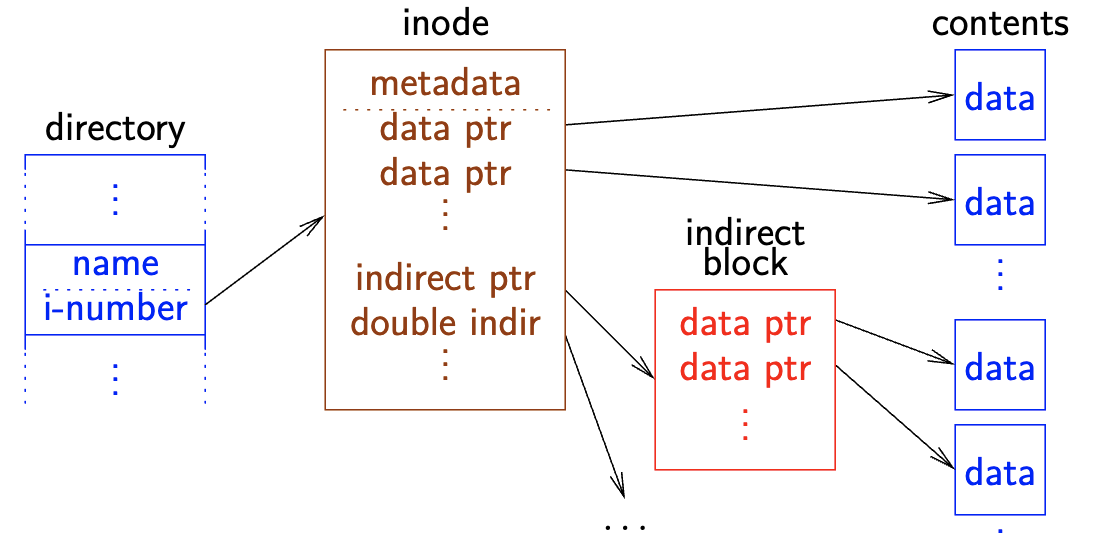
- Each cylinder group has fixed number of
**Inodes**(1 per 2KB data) - The
Inodemaps a file offset → a data block for its file - Also has meta data → permissions, type, etc.
- Each cylinder group has fixed number of