EBS vs. EC2 Instance Store vs. EFS - Know the differences among these storage options for EC2
- ELB:
- Application, Network, and Gateway
- Load balancers are cross-az, can configure this, prob cross-az is better choice
- They are not cross-region. They can load balance among AZ’s
- Know the differences among these
- Health checks are important for load balancers
- Need security groups to manage who is allowed in and out (ports, what
ipsare allowed) - Load balancers have target groups, i.e where they are routing traffic towards
- NLB used for high performance (TCP and UDP)
- ALB used for more general (HTTPS and HTTP)
- An ALB has three possible target types: Instance, IP and Lambda
- Auto-scaling Group
- Use this to automatically scale our servers horizontally (increase the number of instances running if demand is increase, or decrease if not a lot of activity)
- Set minimum capacity and can set maximum capacity
- Can create CloudWatch alarms on certain metrics (CPU usage for example), and trigger auto-scaling from there
- RDS, Aurora, Elasticache
- SQL Database options for our servers to connect to (Elasticache is no-sql)
- RDS has DB drivers for Postgres, MySQL, etc.
- adv. over deploying own DB image: replicas, distribute reads (scales well), restore
- Aurora is managed version by AWS (Serverless) and has more powerful scaling options, scales better, and has more functionality built into it
- Elasticache is just re-packaged version of Redis or memacahed (use redis when we have complicated data structures, and memcached is faster for simple kv pairs).
- Lazy-loading: miss? → read from db and then write to cache, only the requested data is cached
- Write through: when writing to DB, also write to cache
- TTL: Time to live
- Route 53: AWS DNS routing
- Public Hosted Zones: Public hosted zones are DNS zones that are accessible from the public internet.
- Private ones are associated with a VPC → Not accessible from internet and vic versa.
- To access internet from VPC, will need Internet Gateway, NAT,
- Routing policies determine how traffic is routed to your resources, such as EC2 instances, load balancers, or other endpoints → This is mainly what you need to know for Route53
- NACL:
- This is network access control list, which is a firewall-like feature that acts as an additional layer of security for controlling traffic at the subnet level. This is stateless, meaning it does not persist any data remembering anything
- We need to configure both inbound and outbound rules for the NACL
- VPC:
- For this exam, we need high-level understanding of:
- Subnets, internet Gateways, NAT Gateways
- Security Groups, VPC Flow Logs
- VPC Peering, VPC Endpoints
- This is at most 1-2 questions on the exam
- VPC’s are made up of subnets, which is purely a logical concept to organize our VPC: have private and public subnets
- Internet Gateway: Public subnet uses this to connect to internet
- NAT Gateway: Allow instances in private subnet to access internet while staying private
- NACL: Firewall for subnets, this uses security groups to specify what IPs have permission to access subnet
- VPC flow logs record all things coming in and out
- VPC Peering is when you can connect 2 VPC → not transitive: A to B and B to C != A to C
- VPC Endpoint: Allow us to connect with AWS services within our private subnet: S3, DynamoDB
- For this exam, we need high-level understanding of:
- S3:
- S3 is object store, one of the main building blocks of AWS
- S3 has Buckets → no directories (the UI may fool you to believe that), everything in s3 is a bucket. We have the data (the object) and metadata about the object
- S3 Bucket has JSON based policy restricts who has access to an s3 bucket
- Can version the objects inside of an s3 bucket - Deleting a versioned one does actually delete, just changes version
- actions performed before versioning was enabled are not remembered
- Many tiers in S3 - standard, IA, glacier, etc.
- Intelligent tiering moves objects between storage classes automatically with lifecycle rules
- We can configure event notifications on S3 object actions and push these events into things like SQS, SNS, or a Lambda Function
- These services will need the proper IAM permissions to allow S3 to push events to them
- Uploading to s3 is fairly fast, but to do so for larger files, we can consider using multi-upload for files > 100MM. This can parallelize uploads
- S3 has lots of security in place, mostly due to how much basically every AWS service integrates and needs S3 in one shape or the other
- S3 employs SSE, with encryption keys in KMS
- Limitation: KMS has API call limits. When we upload, it calls
GenerateDataKey, which is for envelope encryption. Too many of these API calls may throttle KMS.
- Limitation: KMS has API call limits. When we upload, it calls
- We can also do SSE with CMK (customer managed keys), which are keys managed by us. This will prevent the KMS throttling issues, but means AWS does not managed our encryption keys for us, we need to do it ourselves.
- One could also do Client-side encryption, and upload encrypted data to s3. This avoids all of the above, but them you must decrypt the data yourself when reading from s3.
- To force TLS/SSL encryption in flight, use:
aws:SecureTransport = true - Need CORS configured, this allows browsers to make requests to a different domain. In terms of s3, CORS can be configured to specify which origins are allowed to access the resources (such as objects) in your S3 buckets.
- Pre-signed URLs in Amazon S3 are URLs that grant temporary access to specific S3 objects. These URLs are generated by an AWS SDK or the AWS CLI. Don’t need to give someone access to s3, just give that that, and we can set TTL.
- SDK, CLI
- Ways to interact with AWS via code our through the command line
- Making API calls with the SDK has rate limits → can throttle, in which case, we use exponential back offs.
- CloudFront
- CDN for AWS → caches static results on edge locations so that everyone across a region can have low latency
- Can invalidate data in an edge locations with API with a cache key: every object in an edge location has a cache key
- We can apply geo-restrictions in CloudFront. So, we can explicitly say who has access to the distribution and who can’t (e.g North Korea)
- Might need more notes for this
- Containers on AWS
- Docker containers are the standard in terms of what to run
- Docker images are found in repos like DockerHub, and for AWS, in ECR (can have public and private repos)
- There are 4 services that are really intertwined with Docker:
- ECS
- EKS
- Fargate (Serverless)
- ECR: Holds our docker images
- ECS has 2 launch types: EC2 and Fargate
- EC2 is barebones virtual machines, we must provision and maintain the infrastructure. This gives more fine-grained control, if that is what you need. In this launch type, we would need to run an ECS Agent on each EC2 Instance
- Fargate is serverless, which means AWS abstracts away the provisioning and managing the infrastructure. We just create task definitions (like microservices) and to scale, we increase number of tasks running.
- Can auto-scale EC2 instances but can also auto-scale the tasks running on the EC2 Instance
- ECS Rolling Updates
- Say we are running some ECS containers, and we need to perform updates to our EC2 Instances. We can set minimum and max healthy percentages, so that we can gradually update our instances.
- ECS Tasks
- Tasks are a critical part of ECS. We define tasks in JSON format, to tell ECS how to run a Docker Container. Contains things like image name, port mapping to the EC2 instance (dynamic is the best), etc. In this case, the ALB will find the correct port on your EC2 instance to connect to, but will need security group of EC2 to allow any port from the ALB. This dynamic port mapping is for the EC2 launch type.
- In Fargate, this is abstracted away, and we need only to define the port to show on the EC2 instance.
- Tasks are a critical part of ECS. We define tasks in JSON format, to tell ECS how to run a Docker Container. Contains things like image name, port mapping to the EC2 instance (dynamic is the best), etc. In this case, the ALB will find the correct port on your EC2 instance to connect to, but will need security group of EC2 to allow any port from the ALB. This dynamic port mapping is for the EC2 launch type.
- Each task is like a single docker image, or perhaps one microservice. The point is, we can have multiple of these tasks (docker images) running on one EC2 instance.
- When an ECS task is started with EC2 Launch Type, ECS must determine where to place it, with the constraints of CPU and memory (RAM). It will launch these new tasks on whichever EC2 instance is the most available
- These are things like Random, Spread, BinPack
- When an ECS task is started with EC2 Launch Type, ECS must determine where to place it, with the constraints of CPU and memory (RAM). It will launch these new tasks on whichever EC2 instance is the most available
- AWS ECR is a registry for the docker images, we push our images into this, and pull them when needed.
- AWS EKS is AWS managed version of K8. Provides much more fine-grained control over your deployments. It is an alternative to ECS, but open-source. They are similar in what they do (same purpose, different API to do so)
- AWS Elastic BeanStalk
- This is used for very quick deployments into AWS
- If we don’t want to manage infrastructure, and want to deploy something with your typical 3 tier architecture (ALB + ASG), then using Beanstalk is a quick way to get something like this up and running
- Automatically handles capacity provisioning, load balancing, scaling, application health monitoring, instance configuration → developers only focus on app
- Web-server tier (ELB delegates to EC2 instances), and worker tier (SQS messages polled by EC2 instances)
- Can deploy single instance (one EC2, for dev, one RDS, etc.) and High Availability (ALB, Auto-Scaling, RDS replication, etc. for prod)
- When rolling out updates on this, we have a couple of modes:
- All at once - switch all of them at once
- Rolling - take some down and put some others up, there is downtime
- Rolling with Additional batches - no downtime, create new instances to gradually faze out outdated versions
- Immutable - we make a new capacity-filled version, and just swap everything out at once through a alias change, no downtime, expensive
- Blue-green
- We can deploy with CLI (need a
.ebextensionsfolder in the root directory) or by zipping the project and its dependencies, and uploading via the console- With the
.ebextensions, we can add resources such as RDS, ElastiCache, DynamoDB, etc.
- With the
- This uses CloudFormation IaC under the hood
- AWS CloudFormation
- This is AWS’s own infrastructure as code where we declaratively provision our resources though
.yamlconfiguration files. - With IaC, we can version our infrastructure, save it, and less error prone
- Our CloudFormation templates are uploaded into s3, and from there, CloudFormation references them when creating our stacks. This should be pretty straightforward to read since its in
.yamlformat. - I will come back to update this section after doing so practice problems, to get a feel about how much content of this will be tested…
- This is AWS’s own infrastructure as code where we declaratively provision our resources though
- AWS Integration and Messaging
- SQS: This is AWS Simple Queue Service, a service that helps us build event-driven microservices. We have producers that send messages to the queue, which acts as a message broker, and then publishes these messages to consumers who are polling the queue for incoming messages
- In SQS, every message is for sure consumed, but if it takes too long, it may be placed back into the queue and re-consumed by perhaps a different consumer (this is known as message visibility timeout)
- Once a message has been processed by a consumer, it will delete the message from the queue
- We can scale consumers of a SQS Queue with an ASG
- SQS has in-flight encryption with HTTPS API and also has at-rest encryption with KMS
- IAM Policies regulate access to the SQS API
- SQS Access Policies, like S3 bucket policy, can also be used to allow other services to write to an SQS queue. This is especially true if our consumer and producer are on different AWS accounts
- If some message continually fails, we can send it to a DLQ and if our SQS queue is standard than the DLQ must be of the same type.
- The API for SQS should be straightforward, things like
createQueue,deleteQueue, andsendMessage, just a couple exams, but they’re just CRUD operations with the Queues and Messages - So the standard SQS is not FIFO, messages are not processed int the order they are send to the queue.
- FIFO Queue is another type of SQS queue, and it hashes messages to prevent duplicate messages from being sent into the queue
- In FIFO, there are message groups, where FIFO is guaranteed at the group level
- SNS: This is the pub-sub model of event-driven architecture instead of queue based. Instead of consumers polling a queue for new messages, its the opposite: they are now being notified when a new message is persisted into a topic, which from there, the consumers will go and retrieve the message from the topic
- in AWS, any AWS service can basically push messages into a SQS topic.
- We can publish from many things: AWS Services, SDK, CLI, etc. SNS also has in-flight encryption and encryption at rest
- Popular design pattern is fan out: SNS topic with the consumers being individual SQS topics.
- We also have FIFO topics, but you can probably guess what thats about, so no need to super into detail for this one
- We can filter messages in SNS and route them to specific consumers, so that not every message pushed to the topic and be viewed by every consumer of that topic
- Kinesis: This is an incredibly important service for data streaming and data processing.
- Kinesis data streams are meant to make it easy to collect, process, and analyze streaming data in real-time. In Kinesis, the main services are:
- Kinesis Data Stream: Allows us to stream large amounts of data, modify it in pipeline, and deliver it somewhere for analysis
- Kinesis Data Firehose: load data streams into AWS data stores, or directly pushing things into it to then push to s3 or RedShift
- Kinesis Data Analytics: this allows us to analyze the data in the data streams with SQL or 3rd party like Apache Flinx
- Kinesis Video Streams: capture and process video streams
- Kinesis Data Streams
- Each stream is like a process made up of threads, it is made up of smaller units called shards.
- This makes data streams very scalable, as we can easily add more shards into the data stream to increase throughput
- Partition keys are used for partitioning data records across multiple shards within a data stream
- Records pushed to kinesis data streams can be persisted for long period of time
- When you write a record to a Kinesis data stream, you need to specify a partition key. This key value is used by Kinesis to determine the shard where the record will be stored.
- Producers include AWS SDK, KPL, etc.
- Consumers include AWS SDK, KCL, Firehose, etc.
- To write to this, say from EC2 instance using SDK, will need to use VPC Endpoint
- We have 2 consumer types: Classic and Enhanced
- Enhanced can have a much higher number of consumers reading from one stream, higher throughout, lower latency, but higher cost
- KCL is a java library for consuming data from stream, and there a limit to the number of these that we can have — Each shard is to be read by only one KCL instance:
4 shards = max. 4 KCL instances - We can split shards if say, one shard is much hotter than the rest, or even merge shards, if some are very cold
- Kinesis Data Firehose
- This is kind of like something that consumes from multiple data streams, or directly from the consumer. This is used for ETL pipeline, where we can select, extract and transform data that is moving from our data pipelines. The following diagram is really all we need:
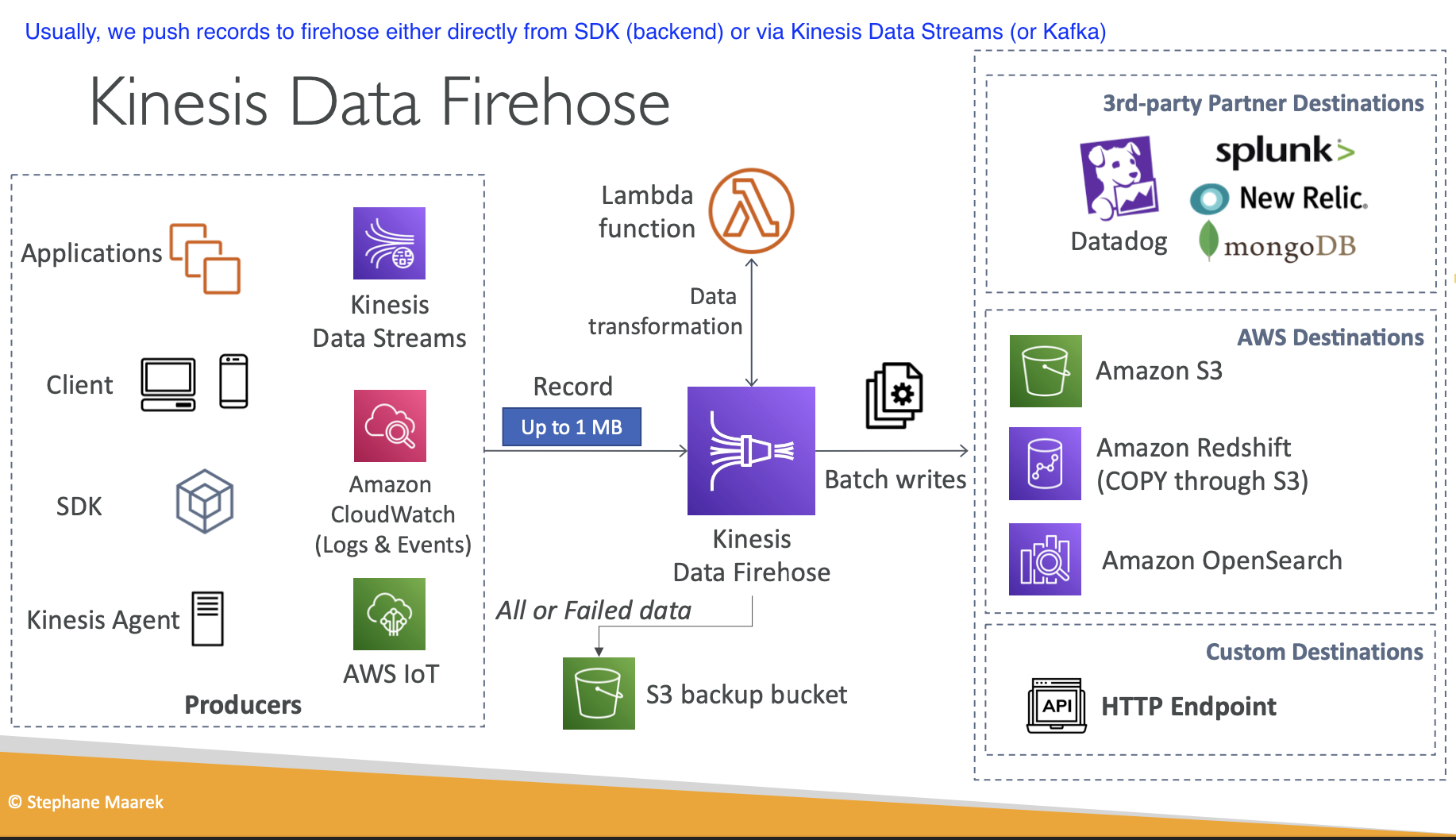
- Kinesis Data Analytics
- This is a service we can use to push data from Firehose or directly from Data streams.
- With this, we can perform real-time data analytics using SQL
- This is serverless (so is Firehose, not data streams though, we need to provision and manage that like shards and whatnot) so we don’t need to manage anything
- Another option is Apache Flink and this works well if we’re using AWS managed Kafka or just want to use OS software
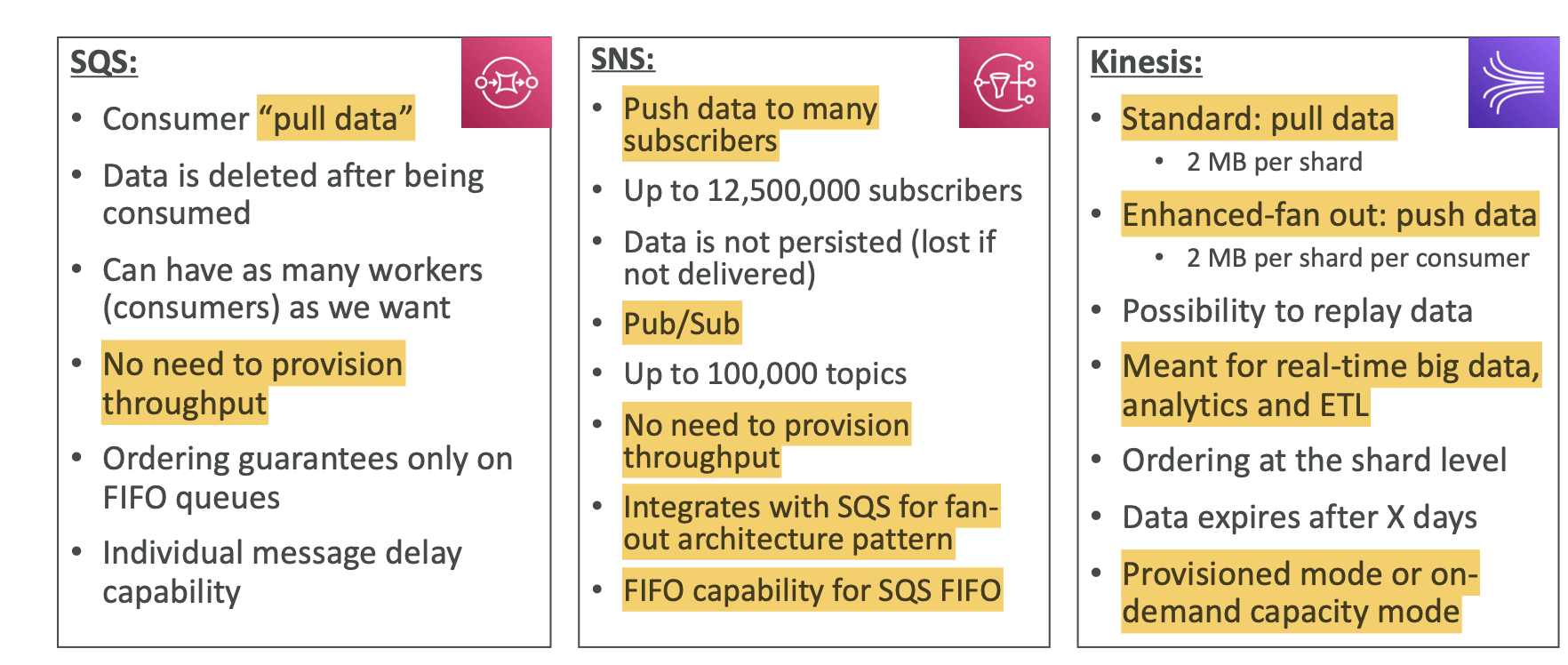
- Kinesis data streams are meant to make it easy to collect, process, and analyze streaming data in real-time. In Kinesis, the main services are:
- SQS: This is AWS Simple Queue Service, a service that helps us build event-driven microservices. We have producers that send messages to the queue, which acts as a message broker, and then publishes these messages to consumers who are polling the queue for incoming messages
- Monitoring, TroubleShooting, Audit
- We use CloudWatch for alarms and for tracking metrics for our infrastructure. There are 3 main services in this section:
- CloudWatch
- X-Ray
- CloudTrail
- CloudWatch
- There are metrics for every AWS service, where we can monitor things like CPUUtilization, Networking, etc.
- EC2 have standard monitoring, but we can get more frequent with detailed monitoring (of course, for a cost)
- We can have custom metrics in AWS, things like RAM usage, Disk Space, etc.
- Logs: CloudWatch Logs is where we can store and analyze logs from our images running on our EC2 instances. We can send these logs to s3, kinesis data streams, Lambda, etc. Sources include: SDK, ECS, Lambda, API Gateway
- We can search through and analyze our logs with CloudWatch Logs Insights, can be queried by AWS own sql-like language
- To log EC2 into CloudWatch, we need to run CloudWatch agent on the EC2 instance to push logs to CloudWatch
- Newer one is called Unified Agent and now we can collect data like RAM, processes on the machine, etc.
- Alarms can be used to trigger certain actions, such as auto-scaling or pushing events or alarms into SQS, for example
- Canary is their version of Cypress
- EventBridge
- This is pretty important. EventBridge is a serverless event bus service where we can send events from different sources, and then EventBridge can route those events to other targets depending on how we configure it.
- Essentially, it just aims to greatly simplify event-driven architecture
- We can do things like cron jobs, event rules to react to a service doing something (uploading object into s3), or trigger functions such as Lambda to send events to SNS/SQS
- We can also configure this to work with 3rd party services like DataDog
- We can have resource policies to control access to event bus, this is important for cross-account event-bridge access
- X-Ray
- This service allows us to view all of our microservices in a graphical view, and allows those with non-technical background help debug
- In microservices, it can sometimes be hard to find where the bugs are, especially with so many microservices talking to each other
- We can trace in X-Ray to see an incoming HTTP request, where it hits, and debug better
- We need
x-ray daemonto be running on our EC2 instances - We need to instrument our code with X-Ray SDK in order for X-Ray to trace requests and know of the existence of our application
- CloudTrail
- Auditing our AWS account
- All history of any action and API call is logged in here. These include everything from the SDK, CLI, AWS Services, and the console.
- We can inspect CloudTrail to see if there is suspicious looking activity. We do so with CloudTrail Insights
- It accomplishes this through intercepting API calls

- There are metrics for every AWS service, where we can monitor things like CPUUtilization, Networking, etc.
- We use CloudWatch for alarms and for tracking metrics for our infrastructure. There are 3 main services in this section:
- AWS Lambda
- This is arguably one of the most important parts of this examination, especially this serverless services
- Serverless means we don’t manage servers, rather, AWS is the one doing it. I just write code that will run on the Lambda function without worrying about provisioning and deploying a server.
- Pay per calls to the Lambda function, we’re not constantly paying for the cost of running a server → Lambda also scales automatically up to 1000 concurrent Lambda function calls.
- Say we have an object uploaded to s3, and use a Lambda
- We can also use EventBridge to trigger a cron job every 1 hour via Lambda
- It is very cheap to run Lambda Functions
- Can have ALB route traffic to synchronously invoke a Lambda Function, the HTTP request gets mapped to JSON, and vic versa for the response.
- We use permission policy to control who can send things to Lambda
- AWS services like S3, SNS, and EventBridge can invoke Lambda functions asynchronously to handle events and triggers
- So we can invoke Lambda sync, async, and the third way is called event-source mapping
- Basically, we just use this to map events into lambda function invocations. While something like s3 is sending some event to our function, for these, it needs to get the event itself. Thats what the source mapping is, it gets the event for lambda, and makes the corresponding function call
- Event source mappings allow you to define a relationship between an AWS service (such as Amazon S3, Amazon DynamoDB, Amazon Kinesis, etc.) and a Lambda function. This connection specifies that whenever a specific event occurs in the source service (e.g., an object is uploaded to an S3 bucket, a record is inserted into a DynamoDB table, or a new message is published to a Kinesis stream), the associated Lambda function should be invoked automatically to process that event.
- Lambda also supports in-order processing for FIFO (first-in, first-out) queues, scaling up to the number of active message groups.
- Event and Context objects in Lambda
- Upon invoking a Lambda function, there are 2 parameters it receives: the event and the context
- The event object contains data that is passed to the Lambda function when it is invoked → e.g API GateWay invoking a Lambda function will pass the request body data through the event object
- The context object is metadata, including things like the AWS request ID, and the name of the Lambda function
- Upon invoking a Lambda function, there are 2 parameters it receives: the event and the context
- Lambda Destinations is a new concept, where we configure to send a result to a destination. This is useful to handling failed events, where we can do something like:
- Send successful events to SQS and failed events into a DLQ
- Lambda needs an execution role when we use it interact with other AWS services → e.g for a Lambda function to send messages into SQS, it needs an execution role that has IAM policy to write to SQS
- Best practice is to create one Execution Role per Lambda Function
- Vic versa, like S3, use resource policies to allow other AWS services to interact with Lambda
- this is a common pattern: resource policy is used by a service to define who has access to it, IAM policies are attached to users and roles, where they specify what actions this entity can perform
- We can have Lambda Environment Variables, which are nice feature to prevent hardcoding certain configuration based data.
- Some examples are: staging strings (“DEV”, “NONP”, “PROD”), API keys → these are all encrypted, and decrypted at runtime when the Lambda function needs to use the strings
- Lambda at the Edge
- We can run Lambda functions at the edge locations of CloudFront, one use case for these is that they can be used to trim and attach some metadata when intercepting HTTP requests. We have 2 flavours: Lambda@Edge and CloudFront Functions, where the latter is for light weight workloads. So if anything we need to do exceeds ~5 seconds, use Lambda@Edge.
- Lambda functions can exist outside and inside your VPC, and by default, are created outside if your VPC. When outside of the VPC, they can access internet, and interact with AWS services like S3 and DynamoDB. They cannot access resources inside a VPC like RDS.
- If you want the function to have RDS, need to place it inside of VPC, and interact with internet through a NAT Gateway, or VPC endpoints for internet access.
- ==REMEMBER, in our public subnets in VPC, EC2 instances have access to Internet, but no Lambda, so they need NAT gateway. ALSO, every VPC that needs internet access needs an Internet Gateway as the entry point for the internet to the VPC. NAT is for things like our private Subnet and Lambda functions in our VPC==
- Keep initializations (Like DB connections) outside of event handlers in Lambda function, since Lambda caches this called context.
/tmp(stands for temp) is a directory where we can store temporary files we may create or need to work with, in Lambda function’s execution. - Another important topic is Lambda Layers:
- This is a method of sharing dependencies → e.g
node_modules,Rust Runtime, etc. This means we don’t need to re-import dependencies every time the Lambda function is called, which is excessive and a waste of resources
- This is a method of sharing dependencies → e.g
- Concurrency limit: up to 1000 concurrent executions, we can set custom limits too, we we should. If we don’t set a limit on some functions, one service may easily scale up and eat up all the capacity, leaving all others to throttle.
- Can also deploy Lambda as a docker image, will need to use the base image from AWS (recommended)
- We should also look to version our Lambda code, which we accomplish through Aliases
- This is how we make deployments, we simply switch which Lambda function an alias is pointing to.
- We can use CodeDeploy to automate this deployment for us
- CodeGuru provides insights into the runtime of our Lambda function
- Lambda Limits:
- Memory allocation: 128 MB – 10GB (1 MB increments)
- Maximum execution time: 900 seconds (15 minutes)
- If we need more than these limits, then we should probably not be using Lambda, and instead, deploy our own servers
- DynamoDB
- Serverless NoSQL Database
- Highly available and highly scalable database
- Very well integrated with data streams, DynamoDB Streams
- We have tables in DynamoDB
- Tables have Primary Key, what can this be?
-
- Partition Key, this needs to be unique for the item, and also diverse so that data is distributed (
user_id)
- Always choose the field with highest cardinality to be the partition key in noSQL database
- Partition Key, this needs to be unique for the item, and also diverse so that data is distributed (
-
- Partition Key + Sort Key, again, combination must be unique
-
- Tables have Primary Key, what can this be?
- Something we need to be comfortable with the RCU/WCU in DynamoDB. There are 2 modes: Provisioned and On-Demand
- Some important terminology we need to know:
- Read Capacity Units (RCU) - throughput for reads
- Write Capacity Units (WCU) - throughput for writes
- We need to know how to do these computations:
- One WCU represents one write per second for an item up to 1KB
- Examples:
-
- we write 10 items per second, with item size 2 KB
10 * 2 * 1WCU = 20 WCU
-
- we write 6 items per second, with item size 4.5 KB (round 4.5 to upper KB)
6 * 5 * 1 WCU = 30 WCU
-
- we write 120 items per minute, with item size 2 KB
2 * (120/60) * 1 WCU = 4 WCU
-
- By default, we have eventually consistent reads (So reading write after write, might not be same). The opposite is strongly consistent reads. One RCU: is one strongly consistent read per second for an item up to 4KB (rounded to nearest multiple of 4KB) or 2 eventually consistent reads.
- Examples:
- 10 Strongly Consistent Reads per second, with item size 4 KB
10 * (4/4)= 10 RCU
- 16 Eventually Consistent Reads per second, with item size 12 KB
1/2 * 16 * 3 = 24 RCU
- 10 Strongly Consistent Reads per second, with item size 6 KB
10 * (6/4) = 10 * (8/4) = 20 RCU
- 10 Strongly Consistent Reads per second, with item size 4 KB
- Now, we can throttle in DynamoDB. How? An easy example is a hot partition, one partition (a popular item) is being read too much
- Exponential backoff
- Can use DynamoDB Accelerator (DAX) if it is a RCU issue → this is a cache for DynamoDB
- The above is for provisioned. In ON-DEMAND, unlimited RCU and WCU, no throttle, much more expensive.
- We should be aware of the API for working with DynamoDB
PutItem,UpdateItem,Conditional Writes,GetItem,DeleteItem,DeleteTable- For write operations, we can make them conditional, so only do them if something else is true
- Conditional writes are also known as Optimistic Locking, which we use to make sure something has not changed before we update or delete it
- We can also query data, using operators like
<=andBegins withand also filter the expression - There are batch operations in DynamoDB and we can query data with PartiQL which is SQL-Like language
- There are indexes in SQL databases. There are similar functionality in NoSQL databases
- Local Secondary Index: Alternative sort key for the table
- Uses the WCUs and RCUs of the main table, no special throttling considerations
- Global Secondary Index: Alternative primary key from the base table
- If the writes are throttled on the GSI, then the main table will be throttled! This uses RCU and WCU external to the main table.
- Local Secondary Index: Alternative sort key for the table
- DynamoDB Streams
- With these streams, we can send events into Kinesis Data Streams, to Lambda, etc. This can be for situations when we would want to react to some event in DynamoDB
- DynamoDB Transactions are when we want to write a lot of things, all together or fail everything. This consumes 2xWCU and 2xRCU
- Examples:
- 3 Transactional writes per second, with item size 5 KB
2 * 3 * 5 * 1 WCU = 30 WCU
- 5 Transaction reads per second , with item size 5 KB
2 * 5 * 2 = 20 RCU
- 3 Transactional writes per second, with item size 5 KB
- Examples:
- What if we have very very large objects? In this case, store in S3 and save a link to it in DynamoDB.
- API GateWay
- Serverless method of building REST APIs
- API Gateway has rollback, and user authentication with IAM and Cognito.
- We can have stage variables, which are just environment variables but for API Gateway. We can use these to, for example, to always have
prodstage variable pointing to a lambda function with the aliasprod, etc. This will make API Gateway automatically invoke the correct Lambda function. This also facilitates deployments (canary) - We can integrate our API Gateway with:
- MOCK for testing purposes
- Lambda Proxy / HTTP Proxy is just proxy, we forward the incoming request to whatever service. There is no mapping for the requests
- AWS Service Integration is same as proxy, but we can add/remove data to the requests and responses.
- We can cache API Gateway responses into API Gateway Cache
- We can provide API keys if we want to regulate who uses our API, and the callers must place this in request header for us to validate. Create API → Generate Tokens → place quotas and limits → associate with API
4xxis client errors (non-aws) and5xxerrors are server errors- Need CORS enabled for other domains to make calls to our API
- Define resource policy for GateWay, to define who can access our API (IAM users)
- WebSocket API
- The above has been for REST API, what about WebSockets? API Gateway has Web-socket option, where the
connection_idis stored in DynamoDB. - We route based on the
actionkeyword, which is stored as a hashtable in API Gateway to the corresponding backend service.
- The above has been for REST API, what about WebSockets? API Gateway has Web-socket option, where the
- AWS CICD
- (CI) Continuous Integration (CD) Continuous Delivery
- AWS CodeCommit is AWS Github, remote repository for code
- AWS CodeBuild is their pipeline for building and testing code, their own Jenkins or Github Actions
- AWS CodeDeploy is deploying to EC2 instances, not on Elastic Beanstalk
- A diagram is best for this:
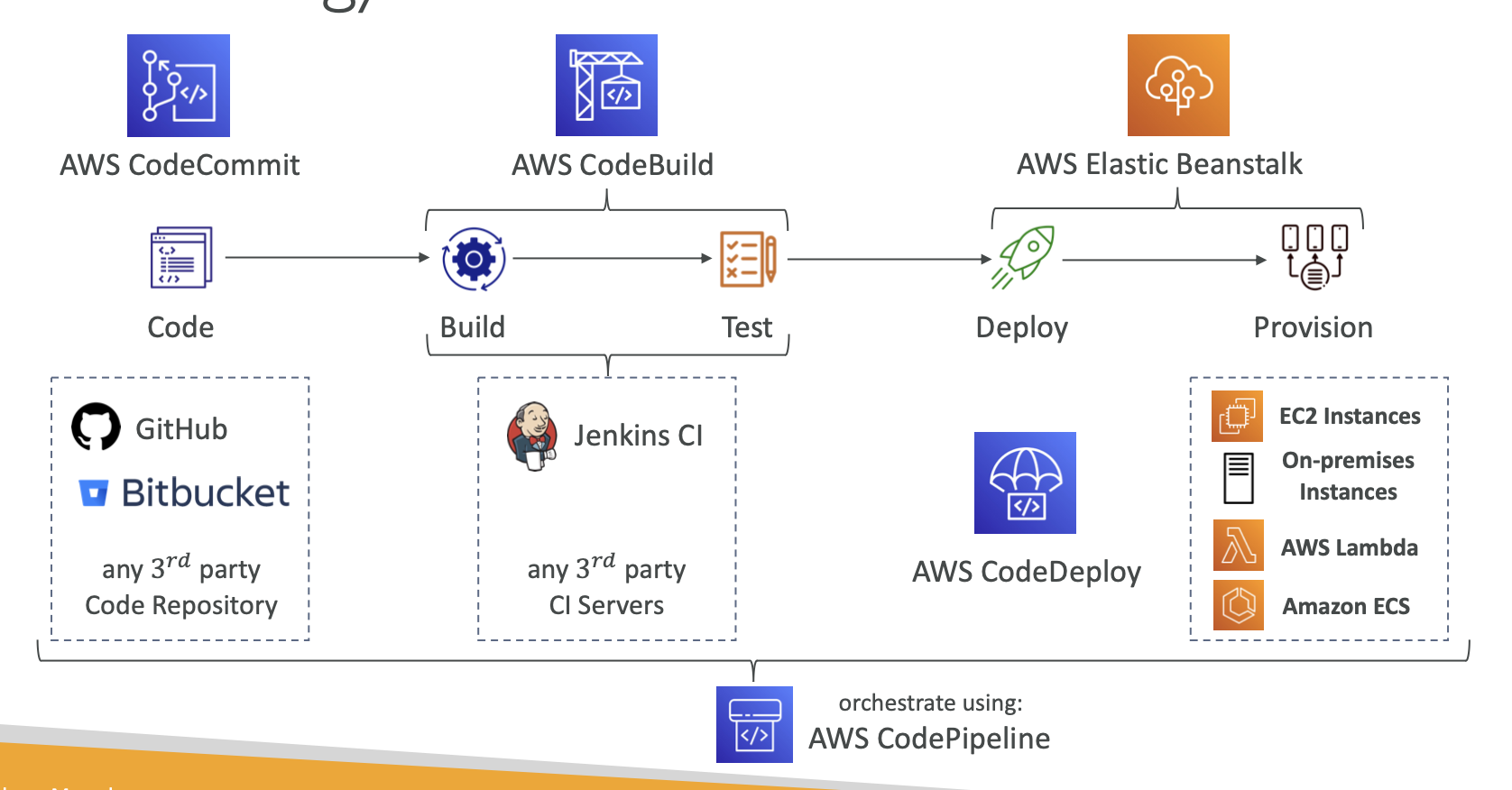
- Whats the difference between CodeDeploy and CodePipeline?
- AWS CodeDeploy is primarily focused on automating the deployment of application code to EC2 instances, Lambda functions, or on-premises servers.
- AWS CodePipeline is a broader CI/CD service that orchestrates the entire release process, from source code changes to deployment, across multiple stages and actions.
- Facilitates the entire process (as seen above)
- Everything that comes out a stage is called an artifact. So the code we pull out of CodeCommit(GitHub), this is an artifact. In order to pass this to CodeBuild, we need to first push this artifact into s3. Then, CodeBuild must read from this to extract the code from s3.
- What if there are errors encountered in this process? We can check CloudWatch EventBridge.
- The below is what how CodeBuild is running:
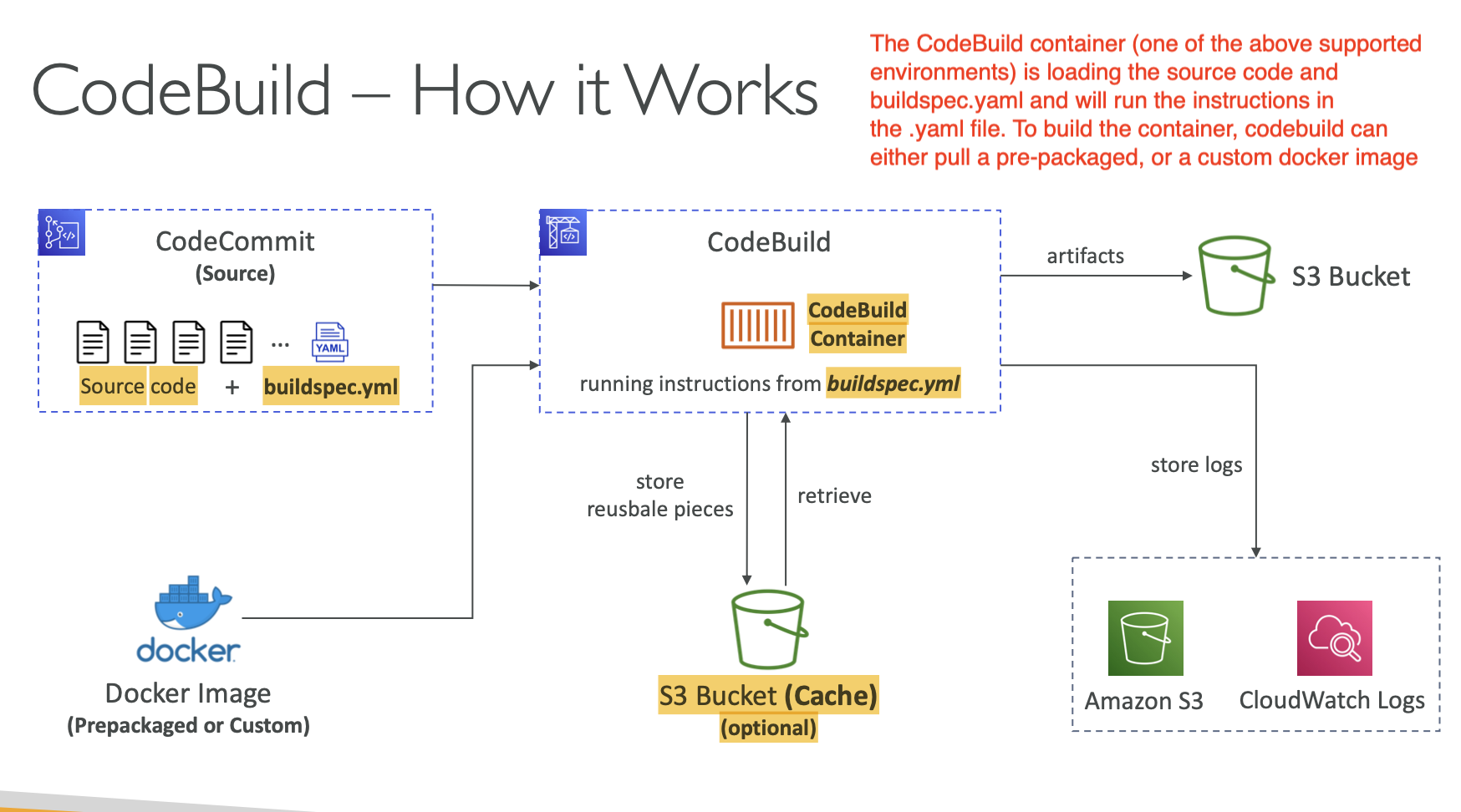
- In the
buildspec.ymlfile, we define:- env
- build phases:
- install
- pre_build
- build
- post_build
- validation
- CodeDeploy automates application deployment
- We define this inside of
appspec.ymlfile (similar to what I did at work) - We need the CodeDeploy Agent to be running on EC2 instances for us to use this
- If a roll back happens, CodeDeploy redeploys the last known good revision as a new deployment (not a restored version)
- We define this inside of
- CodeArtifact:
- Software packages depend on each other to be built (also called code dependencies), and new ones are created
- Storing and retrieving these dependencies is called artifact management
- CodeArtifact is a scalable and secure artifact management service (think JFrog and Ansible)
- We can directly fetch dependency artifacts straight from here
- So when you are doing
npm iin ofi-api, this request is going to Jfrog. Jfrog needs to have those packages availble, and it acts a proxy tonpm. - This is because it can cache it there, and so even if the package is depractaed, or like redis close-sourced, we can still use it. Also, it provides security and so, we can make sure these packages are not malicious and have no vulnerabilities.
- So when you are doing
- As always, we can have EventBridge integration, so perhaps a event is created and sent when pacakage is modified, etc.
- CodeGuru: check our code, Same thing as SonarQube. These are just automated tools to look for vulnerabilities in code, and generate recommendations to address them
- Cloud9 is integrated cloud IDE
- SAM: Serverless Application Model
- This is a framework for developing and deploying serverless applications
- All this configuration is in YAML code
- There are only 2 commands to deploy to AWS → and the exam will 100% test us on this
- This uses CloudFormation under the hood
- SAM can help you to run Lambda, API Gateway, DynamoDB locally
- Good for developing and testing Lambda locally
- Recipe for SAM
- Transform Header indicates it is a SAM template
- Write Code
AWS::Serverless::FunctionAWS::Serverless::Api
- Package & Deploy:
sam packagesam deploy
- How does SAM work? Consider the diagram:
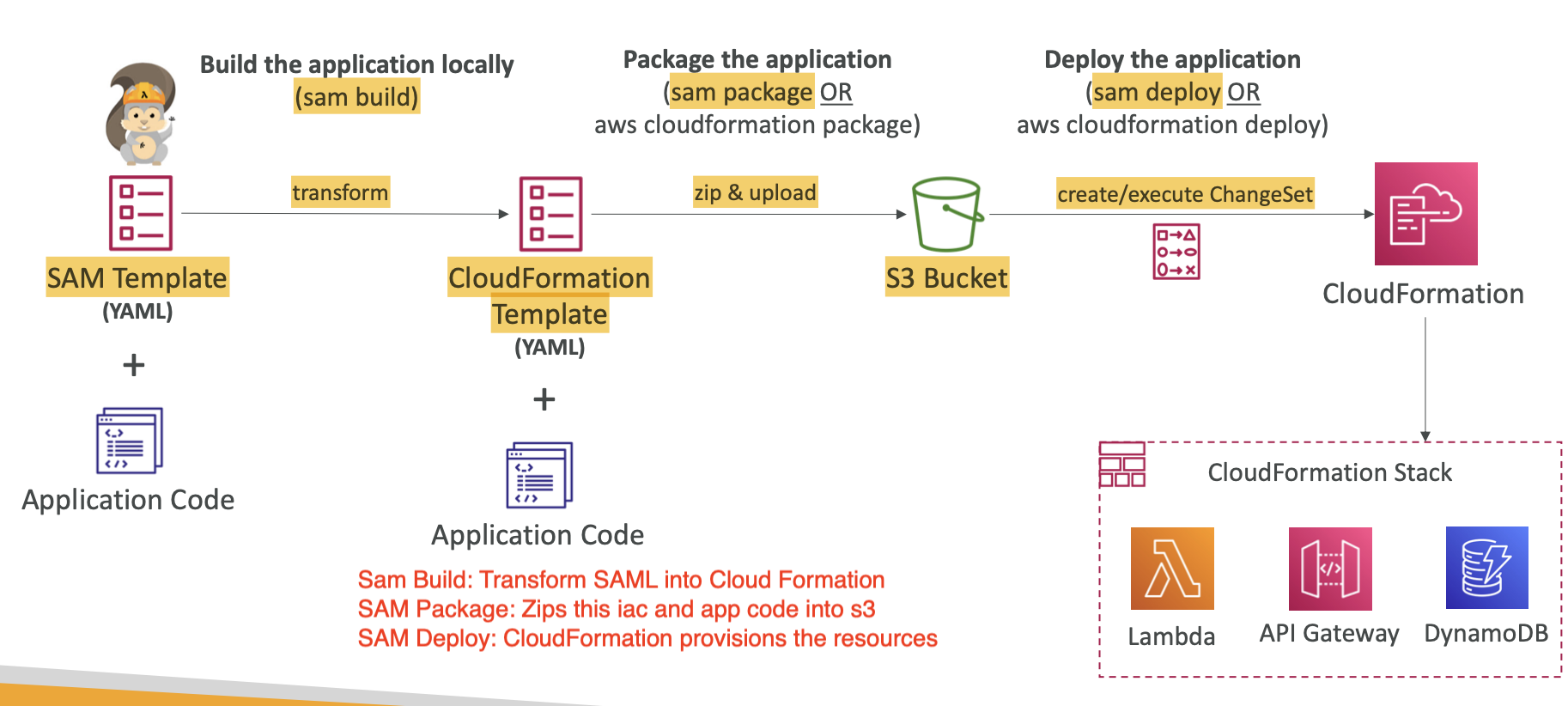
- Sam Build: Transform SAML into Cloud Formation
- SAM Package: Zips this IaC and app code into s3
- SAM Deploy: CloudFormation provisions the resources
- SAM also has CLI debugging, which provides a local environment to run and test Lambda functions, which is ideal for catching errors
- Use SAM policy templates to apply permissions to your Lambda Functions
- AWS CDK
- This is IaC with a familiar language like Go, Python, or Java. This code is “compiled” into a CloudFormation template.
- Main thing we need to know is bootstrapping. That is
- AWS Cognito
- This is AWS on Identity provider. Mainly used for providing those outside of our AWS organization
- 2 main concepts we need to know:
- Cognito User Pools
- This is primarily for sign-in functionality with app users
- Cognito Identity Pools
- We use this to provide entities with temporary credentials, so that they can access AWS Resources directly
- Cognito User Pools
- Cognito vs. IAM
- Cognito vs IAM: “hundreds of users”, ”mobile users”, “authenticate with SAML”, when we have large number of users making accounts, and authenticating, we nee d
- Cognito User Pools (CUP)
- Serverless database of username and password for web apps
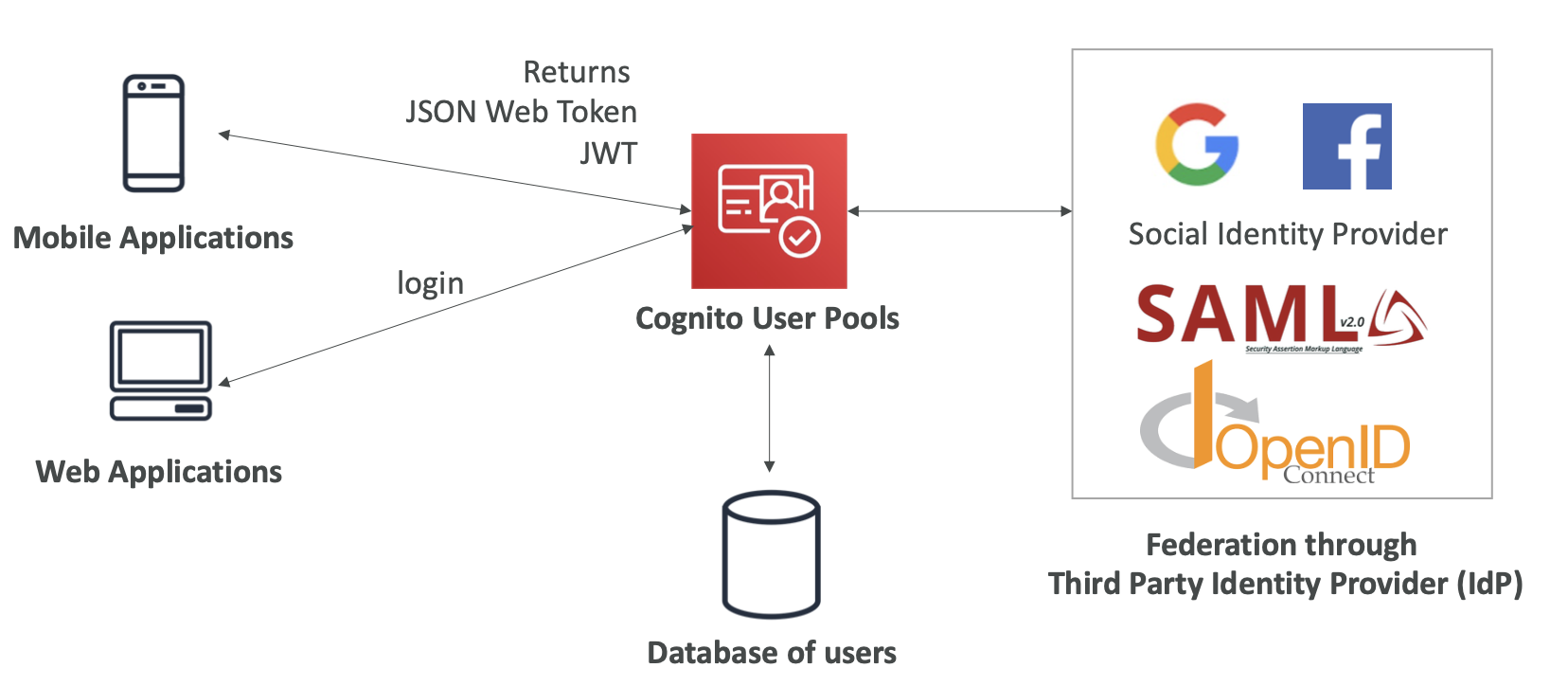
- This is integrates well with API Gateway and ALB
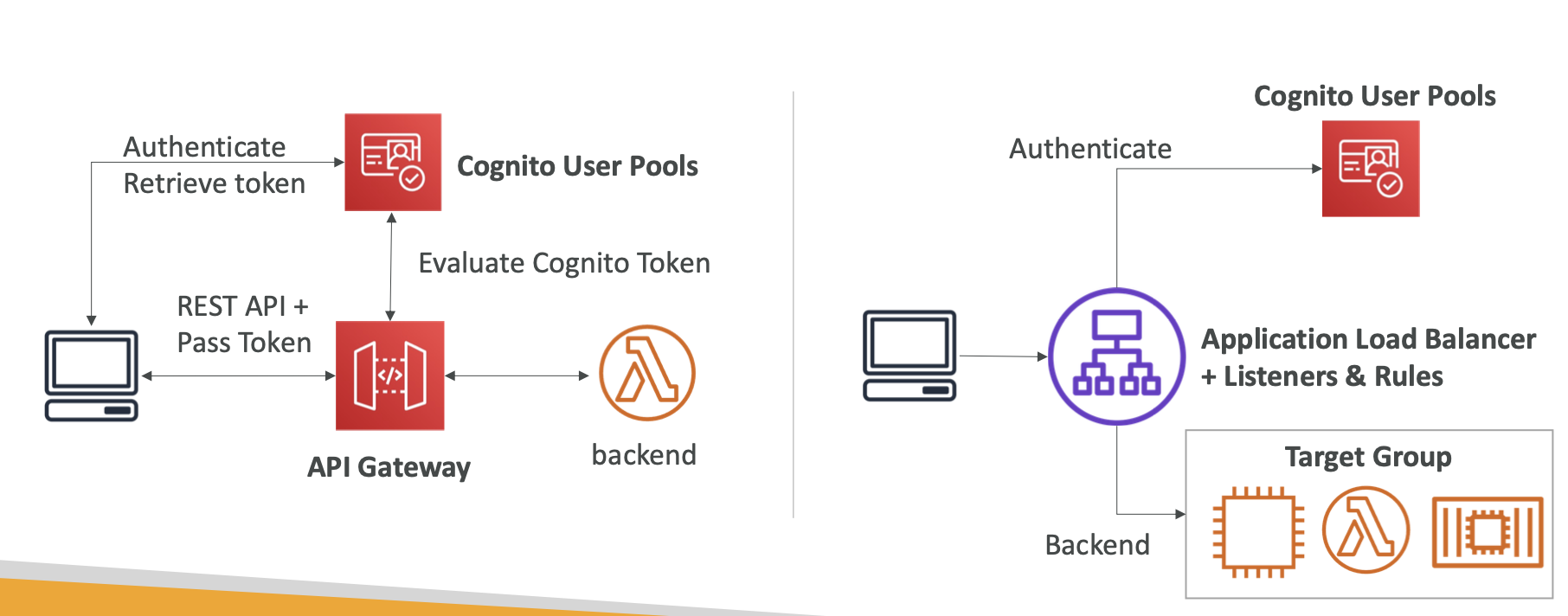
- Cognito User Pools — Lambda Triggers
- CUP can invoke Lambda function synchronously on triggers, which we can use to execute some custom logic on events. For example:
- Pre Authentication Lambda Trigger: Custom validation to accept or deny the sign-in request
- Post Authentication Lambda Trigger: Event logging for custom analytics
- Pre Token Generation Lambda Trigger: Augment or suppress token claims
- This also applies for sign-up, etc. Main point is, we can use Lambda to run some custom logic upon some CUP event happening.
- CUP can invoke Lambda function synchronously on triggers, which we can use to execute some custom logic on events. For example:
- CUP provides us with a custom Authentication UI → Like what Auth0 gives. We can tweak css and styling, but not the underlying javascript.
- This is how authentication would work with a load balancer, working with 3rd party IDP → OIDC means Open ID Connect, which is an Identity Protocol
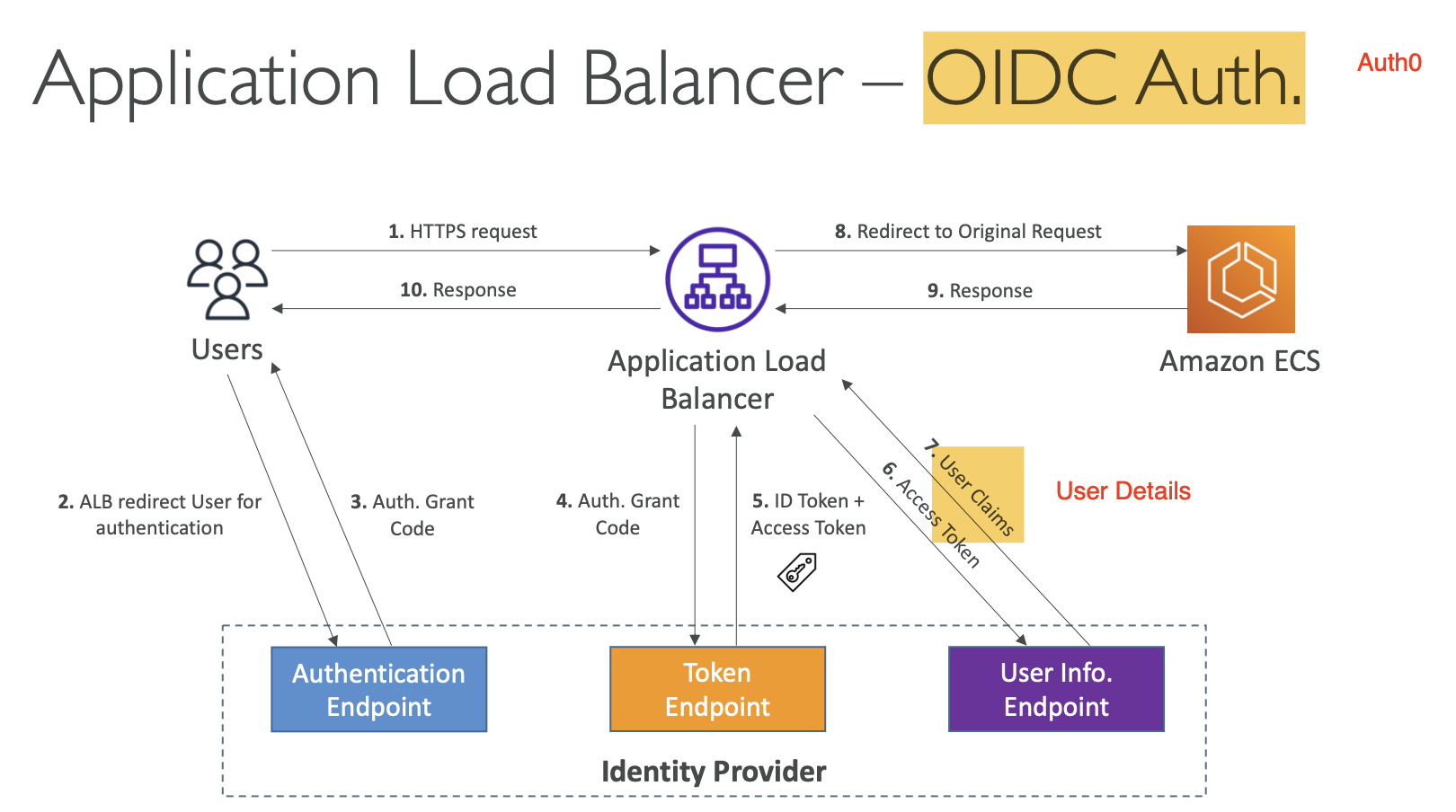
- Will need to configure the OIDC provider to redirect back to our application once we have authenticated
- Cognito Identity Pools
- These are not the same as Cognito User Pools. These are used to allow “users” to gain temporary access to AWS credentials
- We can authenticate these people through public providers like Google, users in CUP, or those in OIDC provider (Auth0)
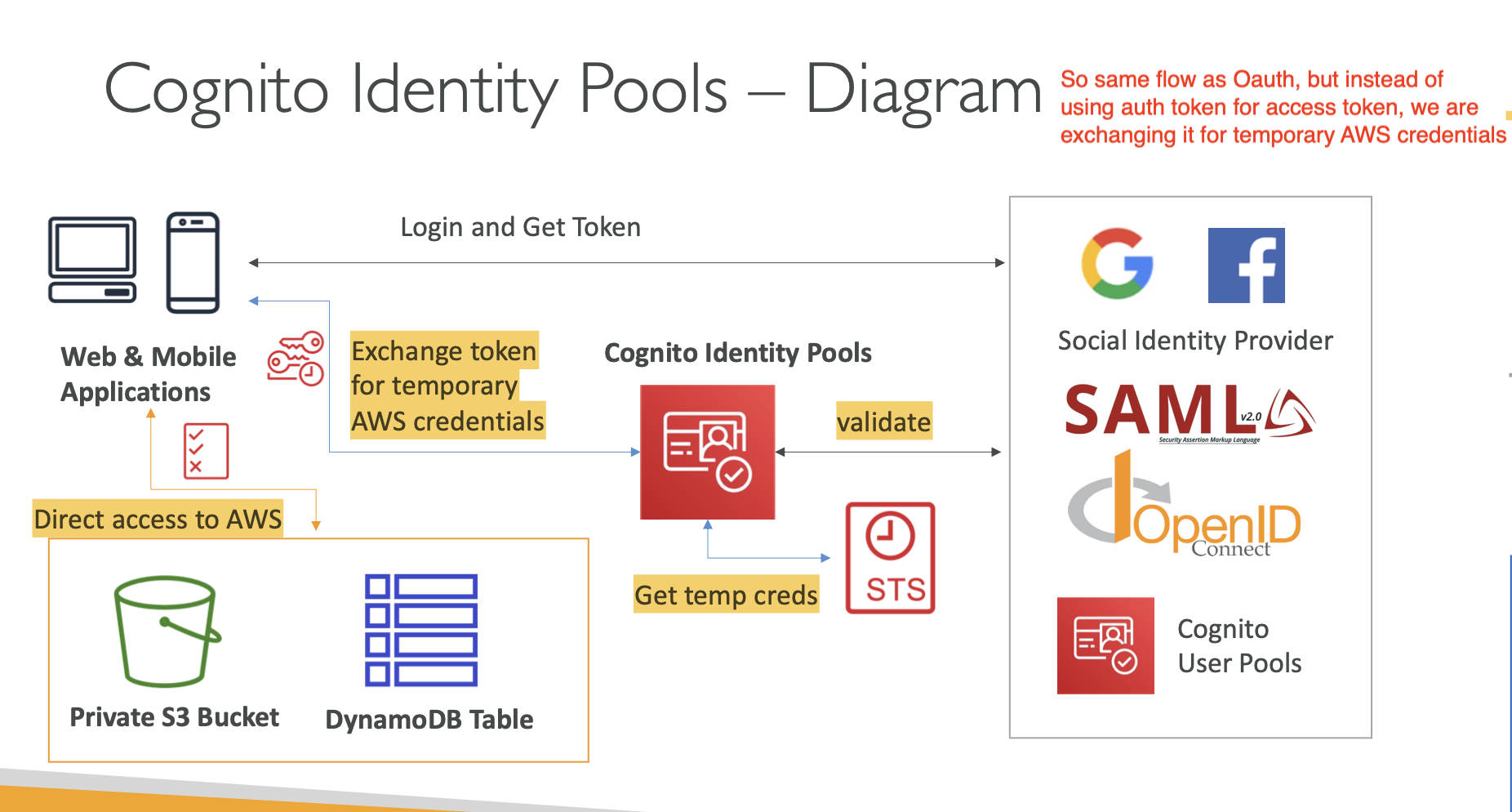
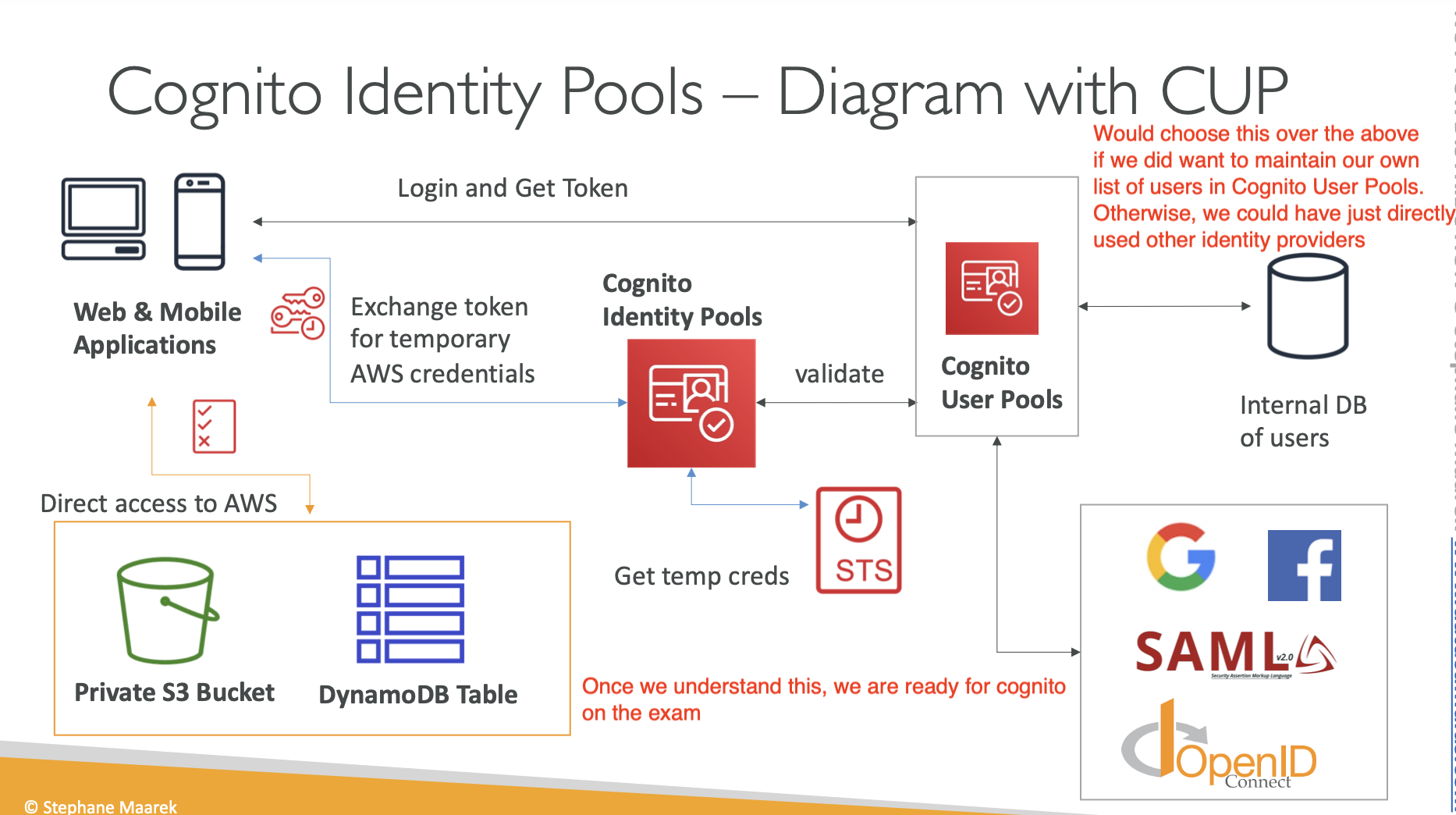
- Just know those 2 diagrams and you’ll be fine.
- AWS Step Functions
- These just orchestrate the direction/flow of a workflow in AWS. They can run Lambda functions one after the other, and wait for some event to be finished, returning a token, before continuing to execute other Lambda functions. There are a couple states that a step function can be in:
- Choice State - Test for a condition to send to a branch (or default branch)
- Fail or Succeeded State - Stop execution with failure or success
- Pass state - Simply pass its input to its output or inject some fixed data, without performing work.
- Wait state - Provide a delay for a certain amount of time or until a specified time/date
- Map state - Dynamically iterate steps.
- Parallel state - Begin parallel branches of execution. (this is important for the exam)
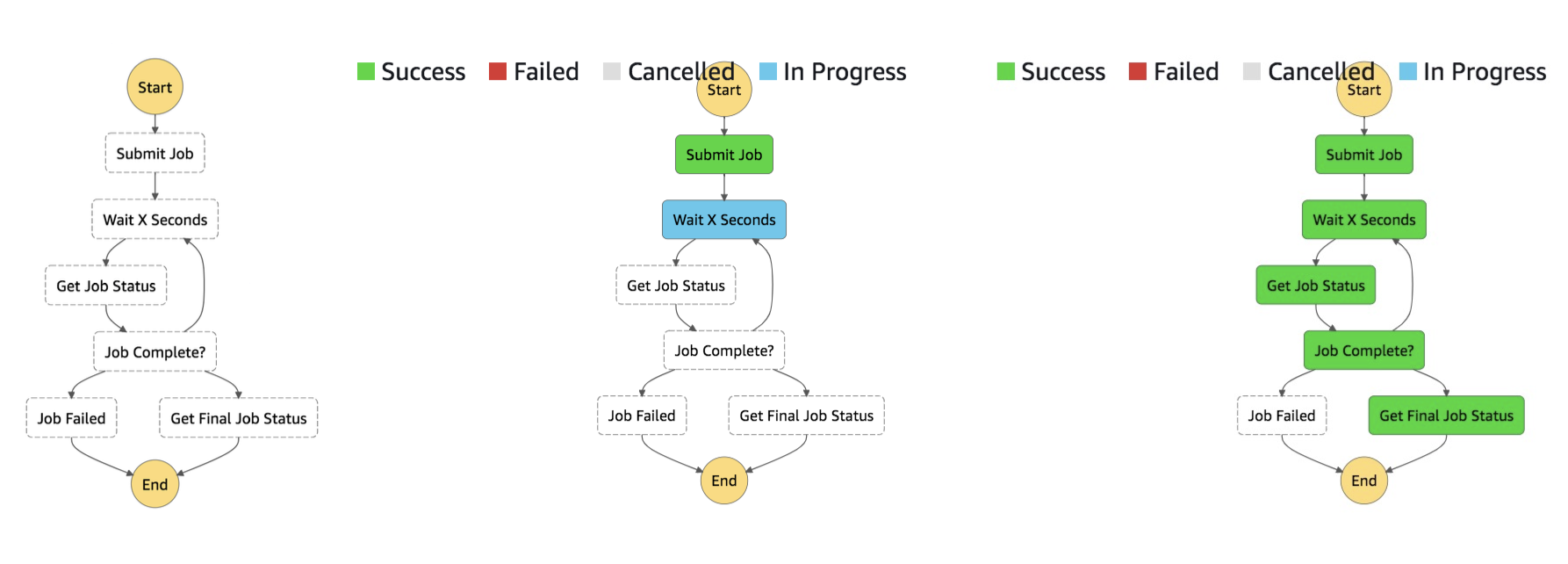
- A special thing we need to know about Step Functions is the
WaitForTaskTokenwhich allows the step function to pause during a task until a task token is returned. Here is an example: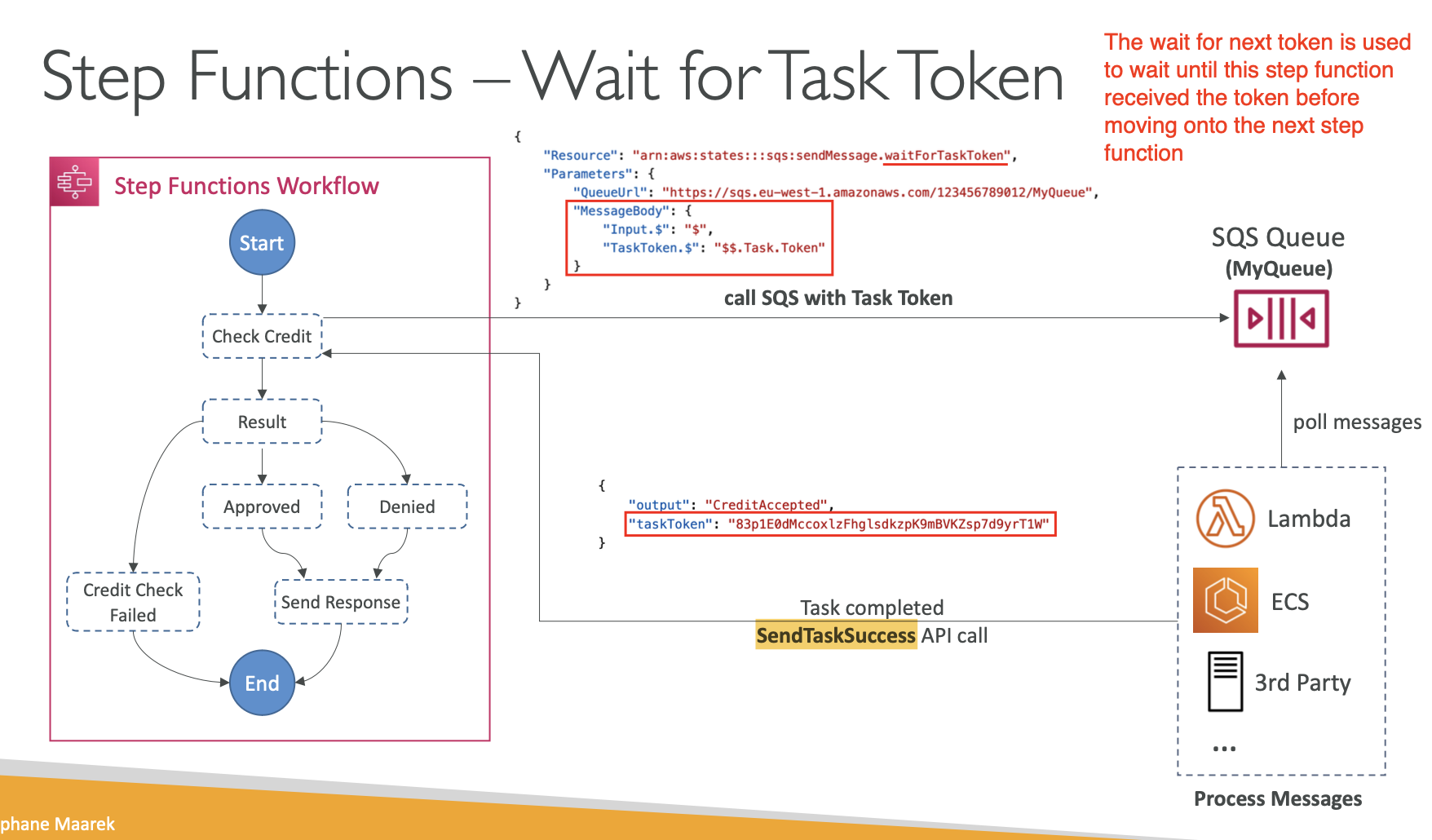
- Have standard and express modes. Standard is for high throughput and long-duration and express is for low-latency and short-duration.
- These just orchestrate the direction/flow of a workflow in AWS. They can run Lambda functions one after the other, and wait for some event to be finished, returning a token, before continuing to execute other Lambda functions. There are a couple states that a step function can be in:
- AppSync
- This is AWS Managed GraphQL API
- Allows us to retrieve real time data with WebSockets, like ApiGateway
- This is AWS Managed GraphQL API
- Advanced Identity
- AWS STS (security token service)
- Allows us to grant limited and temporary access to AWS Resources (up to 1 hour)
- Need to know these API’s at a high level going into the exam. The important ones to know are: AssumeRole, GetSessionToken, GetCallerIdentity, and DecodeAuthorizationMessage
- So, what this is, we define an IAM Role in our AWS account, and we use STS to retrieve credentials and impersonate the IAM role
- This is not used for API user authentication
- Remember:
-
- If there’s an explicit DENY, end decision and DENY
-
- If there’s an ALLOW, end decision with ALLOW
-
- Else DENY
-
- IAM Policies & S3 Bucket Policies
-
- When evaluating if an IAM Principal can perform an operation X on a bucket, the union of its assigned IAM Policies and S3 Bucket Policies will be evaluated.
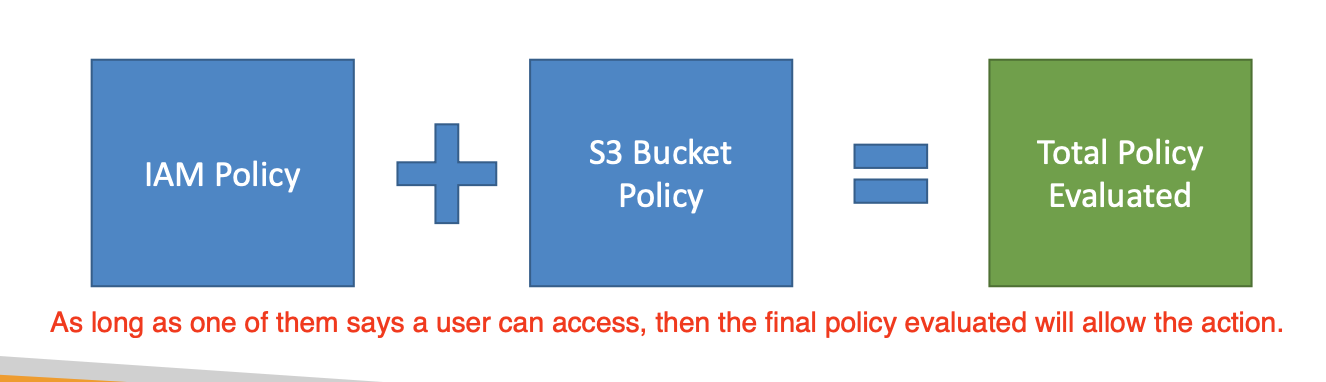
- When evaluating if an IAM Principal can perform an operation X on a bucket, the union of its assigned IAM Policies and S3 Bucket Policies will be evaluated.
-
- AWS STS (security token service)
Here are Notes about things I got wrong in the practice exam
-
In terms of NACL (Network Access Control List), need specific inbound AND outbound rules. An outbound rule must be added to the Network ACL (NACL) to allow the response to be sent to the client on the ephemeral (temporary port used by client) port range.
-
The recommended approach is to define separate Elastic Beanstalk environments for development, testing, and load testing purposes.
-
Max Size for SQS Message is
256KB -
RDS has storage auto-scaling, so instead of migrating to Aurora (which requires a fair amount of infrastructure work), just enable auto-scaling for storage on you RDS cluster
- Updates to your DB Instance are synchronously replicated across the Availability Zone to the standby in order to keep both in sync and protect your latest database updates against DB instance failure.
-
In CloudFormation, we can input custom values to the template when we create a stack. The
Conditionsection allows us to provision based on some conditions, we cannot condition based onparameters.- The only possible fields in CloudFormation are:
DescriptionMetaDataParametersMappingsConditionsTransformResourcesOutputs
- The only possible fields in CloudFormation are:
-
When problem mentions files, think EBS and EFS, not s3.
- Secure Strings in SSM Parameter store. Say we want some critical strings to be encrypted. While we could use KMS, this requires 2 API calls, one for encryption and one for decryption.
- If we want only one API call, can use secure strings. This is when the label for the string is encrypted, but not the value.
-
The term Gateway Endpoint refers to VPC endpoint
-
RDS Standby are not for reading, only for durability and disaster recovery, which is sync. This is not what is meant by “scale RDS reads with read replicas”, these are not read replicas.
-
To encrypt messages in SQS → enable SQS KMS encryption
-
CDK Steps are:
- create app from CDK CLI
- Add code to app to create resources
- Build (optional)
- Synthesize one or more stacks in the app
- deploy to AWS account
-
Some HTTP Error codes:
- 503: no target groups for the ELB
-
If need IAM Authentication for RDS, use MySQL or PostgreSQL drivers.
-
You cannot change SQS type: Standard ←/→ FIFO
-
Sticky sessions are a mechanism to route requests to the same target in a target group from the ELB
-
Signed URLs for Amazon CloudFront distributions are URLs that grant temporary access to private content served through CloudFront. Just like signed s3 object urls.
-
CodeCommit is a managed version control service that hosts private Git repositories in the AWS cloud. We can authenticate via:
- Git credentials
- AWS Access keys
- SSH Keys
-
Remember, to have ELB delegate over regions, need to specially go and configure this. It does go cross-az by default, but not cross-region.
-
In CLI, to stop instances in a another region, just use the
--regionparameter. -
If we have throughout error in Kineses Data, then we must decrease the frequency or size of requests in addition to retrying failed messages with exponential backoff.
-
Dedicated Instances are Amazon EC2 instances that run in a virtual private cloud (VPC) on hardware that’s dedicated to a single customer.
- Spot is the cheap one, runs whenever capacity is available
-
The only resource-based policies for IAM is trust policy - specifies which principals can assume which role
-
To deploy SSL/TLS certificate: AWS Cert. manager and IAM and ELB
Mappings:
RegionMap:
us-east-1:
HVM64: "ami-0ff8a91507f77f867"
HVMG2: "ami-0a584ac55a7631c0c"
For this, !FindInMap [ MapName, TopLevelKey, SecondLevelKey ] since we have 2 “layers” in the mapping.
-
X-Ray sampling, in the context of AWS X-Ray, refers to the process of capturing and recording traces of requests as they flow through a distributed system.
-
AWS Cognito Sync is a service provided by Amazon Web Services (AWS) as part of the AWS Cognito suite. It enables developers to synchronize user data and preferences across devices and platforms securely.
-
AWS KMS does support sending data up to 4 KB to be encrypted directly, anything more (like 1MB), we will need to use envelope encryption
-
A route table contains a set of rules, called routes, that are used to determine where network traffic from your subnet or gateway is directed. The route table in the instance’s subnet should have a route defined to the Internet Gateway.
-
Transactions are a way to have all or nothing behaviour in DynamoDB. Same thing is available in RDS via Transaction blocks
-
UpdateItemaction of DynamoDB APIs, edits an existing item’s attributes or adds a new item to the table if it does not already exist. -
Use the AWS CLI —dry-run option: The —dry-run option checks whether you have the required permissions for the action, without actually making the request, and provides an error response.
-
To maintain the same number of instances, Amazon EC2 Auto Scaling performs a periodic health check on running instances within an Auto Scaling group. When it finds that an instance is unhealthy, it terminates that instance and launches a new one.
-
Can make Amazon Simple Queue Service (SQS) to handle messages larger than 256 KB by employing the Amazon SQS Extended Client Library
Lambda Memory Limit - The maximum amount of memory available to the Lambda function at runtime is 10,240 MB. S3 Events are a thing, can react upon them → say something inserted an object, can use Lambda to react to an s3 event (not cloudwatch or eventbridge)
GSI vs LSI:
- Use Global Secondary Indexes (GSI) when you need to query data based on attributes other than the primary key and when those attributes may span multiple partitions.
- Use Local Secondary Indexes (LSI) when you need to query data based on attributes other than the primary key but within the same partition as the table’s primary key.
How should we move code from GitHub to CodeCommit over https?
- Use Git credentials generated from IAM
CodeCommit is automatically encrypted at rest, we don’t use KMS for this (should have guessed this).
Encrypting S3:
- If we want to use
SSE-S3, then when we upload objects, need to specify to use AE256 encryption: `x-amz-server-side-encryption’: ‘AES256’
There’s that typical question of “hey my users keep being logged out, and I have multiple instances that process incoming requests, how to fix?”:
- The normal solution is to enable sticky sessions, which means one instance the user connected to before is likely to receive that user again. This needs the ALB to be maintained
- If the ALB is being replaced completely, then need some type of caching
If we’re building our project in CodeBuild, and its taking very long times to build our dependencies, we can cache these dependencies in s3 to speed up build times.
Kinesis Agent is a stand-alone Java software application that offers an easy way to collect and send data to Kinesis Data Streams. Whats the difference between this and KPL? KPL is merely acting as an intermediary between producer and kinesis. On the other hand, kinesis agent automatically continuously monitors a set of files and send new data to your stream.
CloudFormation CLI:
- The
cloudformation packagecommand packages the local artifacts (local paths) that your AWS CloudFormation template references. The command will upload local artifacts, such as your source code for your AWS Lambda function. - The
cloudformation deploycommand deploys the specified AWS CloudFormation template by creating and then executing a changeset.
SSE-C means server-side encryption with customer keys → this NEEDS to go over HTTPS, whereas things like SSE-KMS and SSE-S3 don’t need HTTPS as they are encrypted at rest by default
PlaintText vs SecureString in SSM:
- Use PlainText parameters for non-sensitive data that doesn’t require encryption.
- Use SecureString parameters for sensitive data that should be encrypted at rest to comply with security best practices and regulatory requirements
- SSM API calls are simple, so if questions is asking for simple, choose this. Then, we can store as plaintext or secure string depending on whether we are required to encrypt the secret strings.
Remember, the header 'x-amz-server-side-encryption': 'SSE-S3' is invalid, to upload objects to use s3 SSE encryption, we use the AE256 TYPE. IN FACT, there is no valid header that specifies via SSE- something. So for kms it is: aws-kms