Let’s first start off with what is regression. Broadly, regression is a practice used to analyze the relationships between variables, specifically and independent variable and a dependent variable. When we perform regression in machine learning, we are, given a dataset, trying to predict future values. For example, say we have are trying to predict housing data from some other data such as crime rate, education etc. Solving this problem is regression, and we will see in this chapter, how we can create models to predict on this for us.
💡 Idea: Given a training data , find a function , such that where
- : the feature vector for the training example
- : responses
So, each data point is some vector, and the response, could be anything from a simple scalar value (think predicting something like stock price), to higher dimension vectors (perhaps we’re predicting multiple traits).
-
In theory, for any finite training data set, there exist an infinite number of functions such that for all , we have . Consider something like:

-
So, we must be careful about how we fit our model/function to the data. Unlike in classification tasks as simple as perceptron, where 100% accuracy on training data is normal, we don’t want our model to perform exceptionally well on our training data. Here are some examples of functions found after training to a training data set:
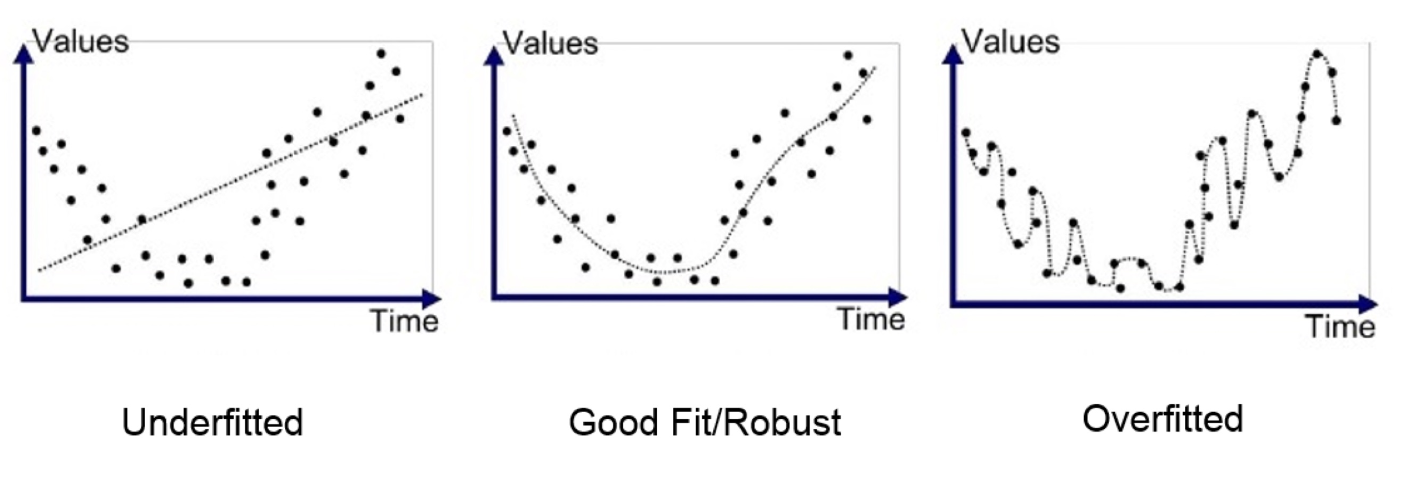
-
What do we see here? If we find a function, that does indeed correctly and precisely predict in our training set, chances are, it has poor generalization, which defeats the entire purpose of machine learning in the first place. This thought process is reflected in all aspects of deep learning, and especially will become important topics upon learning more powerful models.
is our optimal function. That is, it is the best possible function, as it we know:
Here, is the theoretical regression function, the function that minimizes the expected squared error between the predictions and the actual values . Of course, requires us to know the distribution of both and , which is infeasible for real world data. The goal is to learn an approximation of the true regression function using the samples in our training set. The primary objective in machine learning is to find the function that generalizes well to new unseen data. One method to improve generalization and reduce over-fitting is cross-validation, which is something we will see later in this chapter.
Before we jump right into how machine learning models learn in regression, its best to start of by considering what characteristics of the regression function should be pay attention to for the model to improve itself. To see this, we need to analyze the error of models. In the above, is the function our model is predicting, and we want to see at a more granular level, where the error of our model is from. This is why we do bias-variance decomposition, as it helps us to understand the sources of error in our model and guides the model in how to lern and improve in the next training iteration. Here is an derivation of the decomposition:

As seen, there 2 components that have surfaced. The noise (variance term) is independent of and represents the irreducible error inherent in the data. So, to improve our model, we need to minimize the bias, hence, the square error between the regression function and our predicted function. How can we do this? If we can get as close as possible to , we will minimize our error. So, this echos the goal of machine learning in regression: finding function that approximates .
To do so, we introduce the notation:
This represents the empirical estimate of the expected error between the model predictions and the true outcomes. This is reflects how well our model performs on the given dataset in terms of predicting the outcomes . In ML, we have a sort of lemma, which is:
Uniform Law of Large Numbers: as training data size , then our estimate will become closer and closer towards the real value
So, this has been an overview of regression, and an entry into what we are looking to accomplish with linear regression. We’ll look at one(and the most important) example: linear least squares regression
Linear Least Squares Regression
This is the idea of linear regression and we are trying to minimize the squared distance from the the predicted value to the actual value — Least Squares. This is our loss function and the method in which our regression model will learn. Let’s re-introduce some notation moving forward:
→ Linear Least Squares Regression
Our regression functions are affine. They will be of the form:
where:
- = # of response parameters we want to predict z3e45rt!Q.
- = # of input parameters
Again, we can pad our function like before to make it more concise to write:
So, we can express Chapter 2- Linear Regression using matrix form:
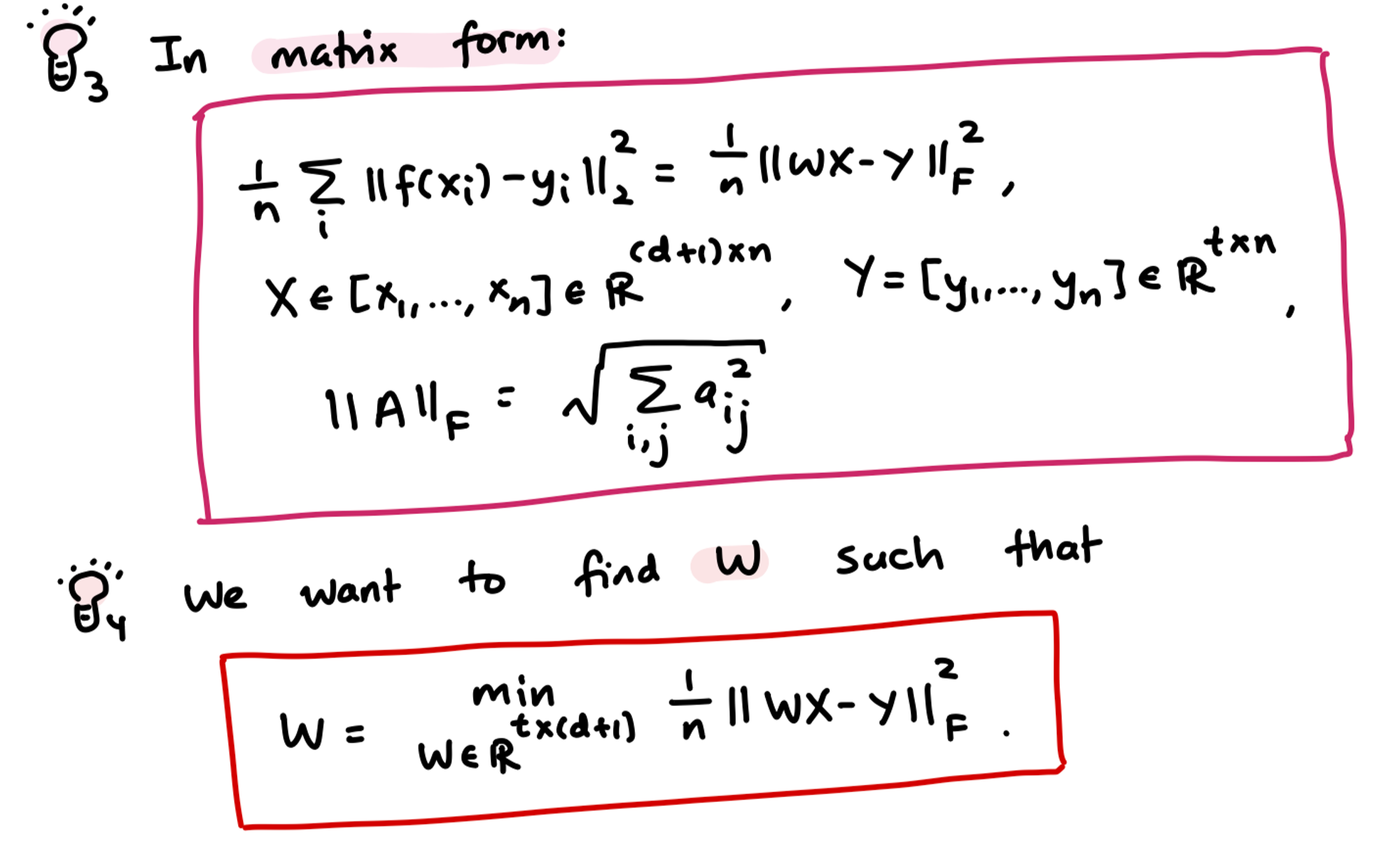
- Quick note on ==== and the use of it in the above
- a way to measure the “size” of a matrix that generalizes the notion of the Euclidean norm of a vector to matrices. It is defined as the square root of the sum of the squares of all the elements of the matrix.
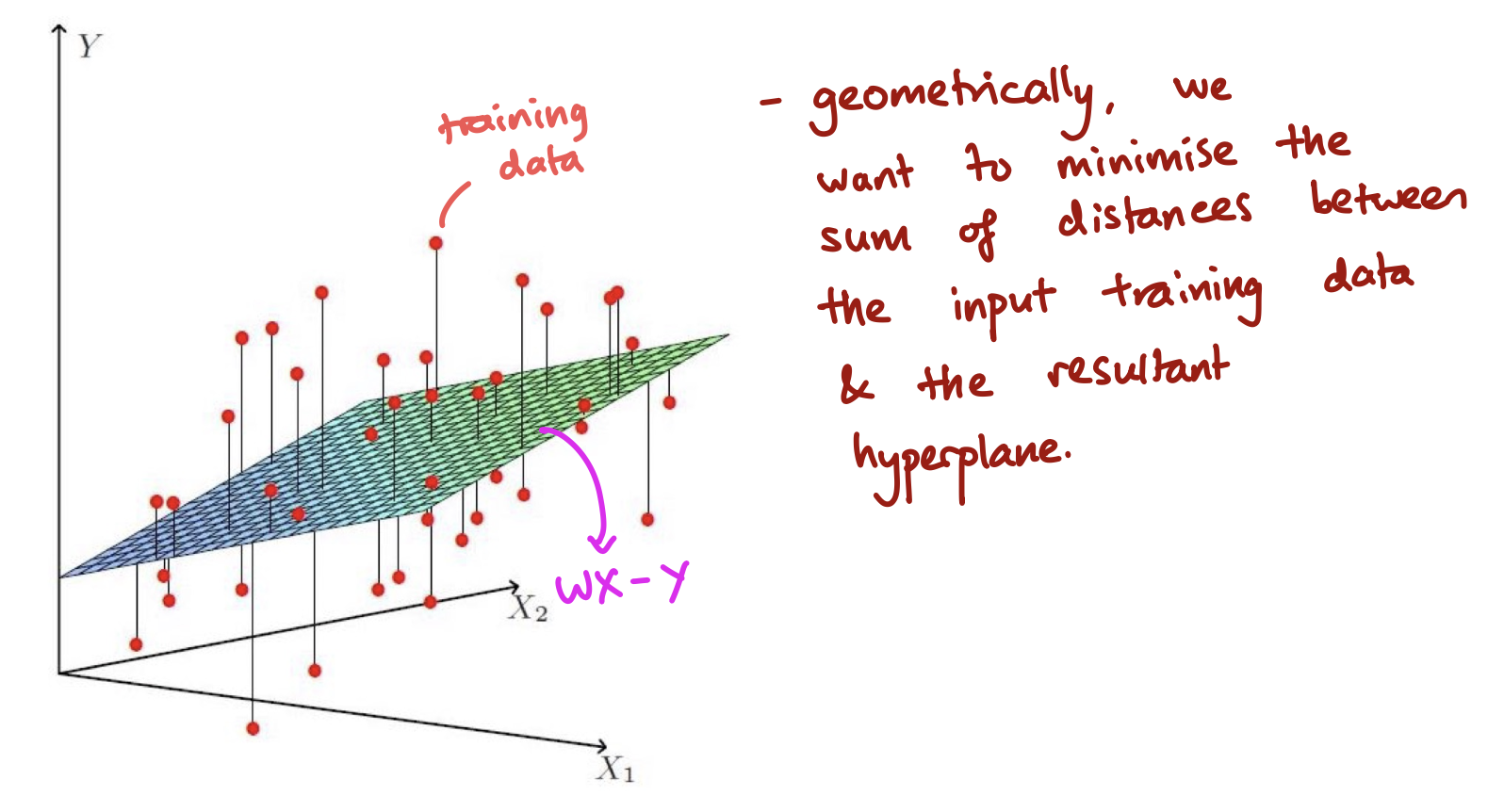
Ok, so we have what we want to use to find our model weight , how should we go about solving this linear regression. The above formulates what the objective function is that we are trying to minimize. To move forward, we need to start looking at how the model will take the mean squared error and learn from it. So, we have this loss function that is mean squared error, and we need to derive from a this, a value to adjust our model weight. To do this, we need to find the derivative of the loss function, and apply gradient descent. Before we can jump into this, we need a review on some of the concepts in calculus, which we will see now.
Calculus Detour
Let’s consider the function be a smooth real-valued function. We fix an inner product, and define the gradient as:
Something to note — The symbol is called the “restriction” symbol in mathematics, so in the above, we are restricting the expression or operation to the case where
We will fix an inner-product, which just means to define some affine operation between the 2 values being dotted. Also, recall what the gradient represents: gradient of a function points in the direction of the greatest rate of increase of the function. To break down the above, we re-visit some multi-variable calculus knowledge.
→ Directional Derivative
In multivariable calculus, the directional derivative of a function at a point in the direction of a vector measures the rate at which the function changes at as you move in the direction of It tells you how fast the function is changing at if you move in a specific direction. Mathematically, the directional derivative of at in the direction of is given by the dot product of the gradient of at and the unit vector in the direction of :
Where:
-
is the gradient (vector of partial derivatives)
-
is the unit vector in the direction of
Let’s see a quick example. Consider the function . Graphically, it is:
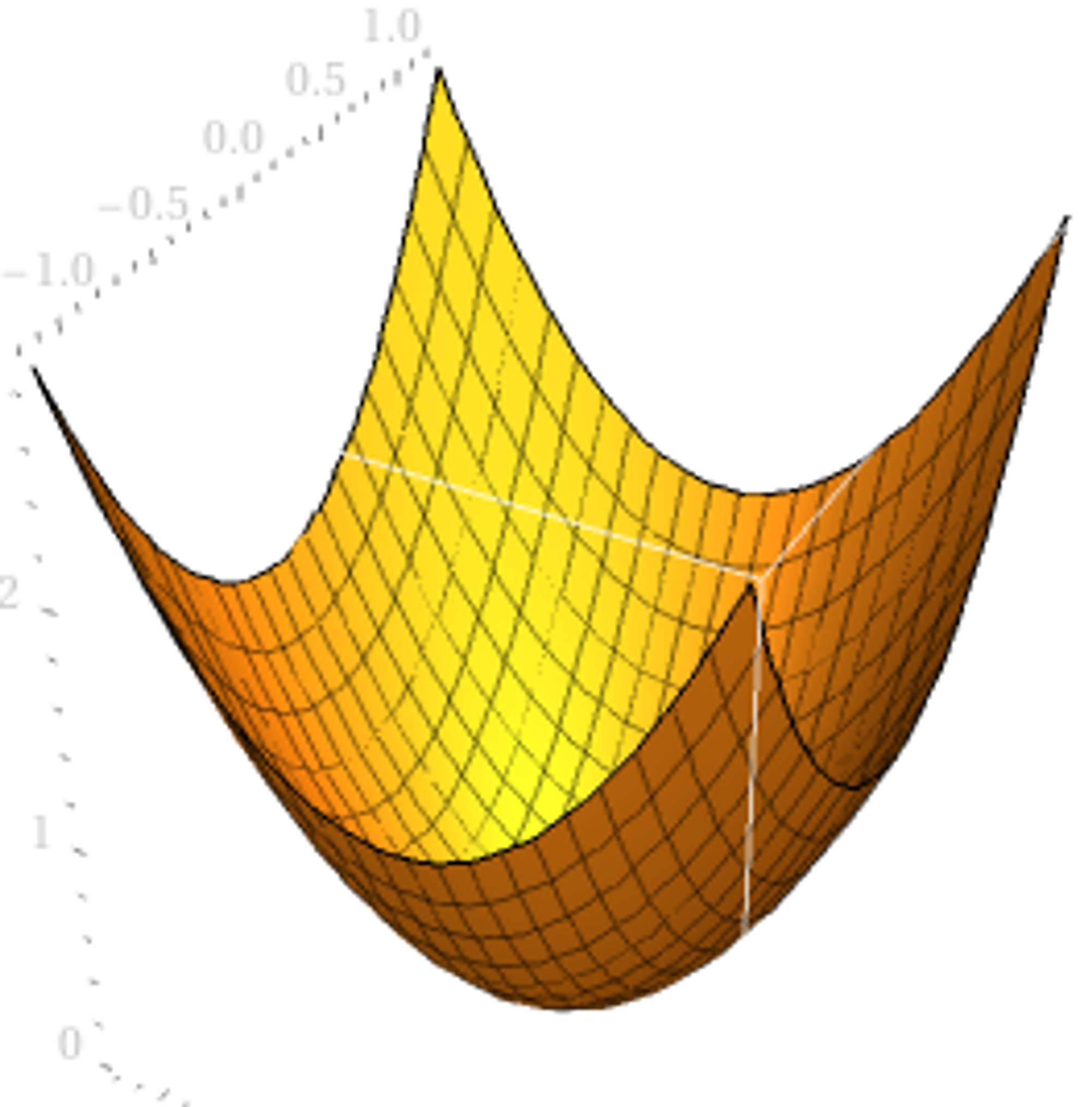
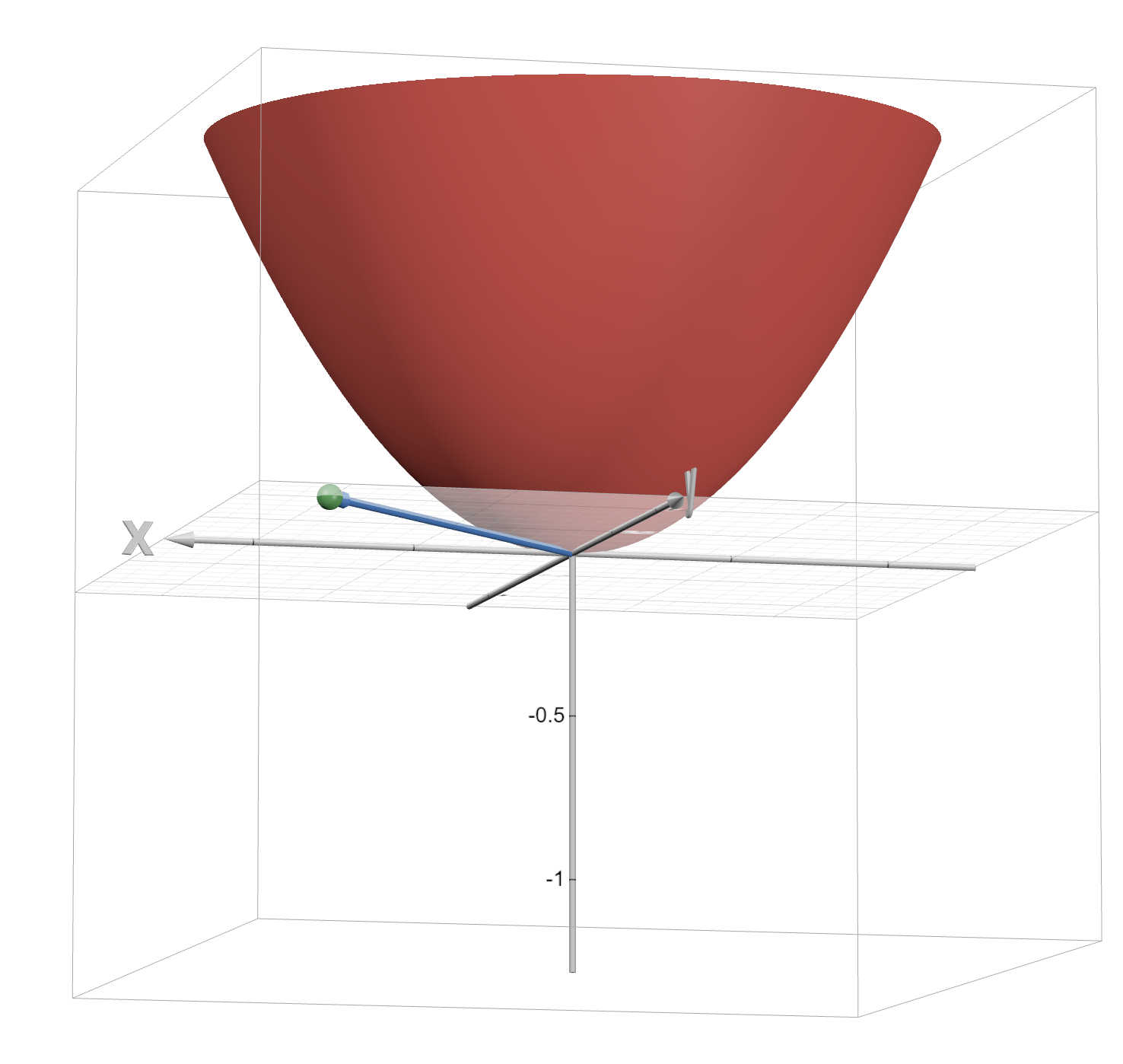
Let in the direction of the vector . So, on the right, we see all 3 plotted.
- Gradient of :
-
- Unit vector in the direction of
- Normalize into a unit vector:
- Compute the dot product:
-
So, this means the directional derivative is . So, it is now very obvious what we are trying to use this for: we will move the data point in the opposite direction of the gradient, as to move ourselves towards a local minima, minimizing mean squared error, and therefore improving the performance of the model.
Moving back to the Chapter 2- Linear Regression, we recognize that this is simply saying the rate of change in our regression function , near the point , along the curve at , is equal to the rate of change of at in the direction . So, why is this important? This gradient is what we are looking for, and we obtain it through finding the derivative of the loss function. The following examples cover some of the calculus aspect of this:


Small note on the quadratic function: This is a quadratic function for vector variables
-
-
-
This term resembles the 1D Vectors: . So, is the quadratic term, as all variables in are multiplied against each other, with some constants in . Same applies for and
So, now we have looked the basics of calculus needed to compute the direction for learning. We move onto the next topics
Optimality Condition
Theorem: Fermat’s necessary condition for extremity
If
is a minimizer (or maximizer) of a differentiable function over an open set, then
A.K.A, we’re looking for local/global minimum for our loss function. We know have the tools to solve linear regression. So, we define the loss function:
What does the subscript mean? The Frobenius norm of a matrix is a measure of the “size” or “magnitude” of the matrix. It is defined as the square root of the sum of the absolute squares of its elements. It is the extension of the seen for vectors.
Taking the derivative of this, with respect to and making the derivative equal 0:
So this is our model weight. Once we have solved for on the training set , we can predict on unseen data : , where is the predictions our model makes on test data. The “test error” (if true labels were available):
The training error is:
We will reduce the training error to reduce the test error.
Ill-Conditioning
Ill-conditioning in machine learning, particularly in the context of numerical optimization and linear algebra, refers to situations where a problem is sensitive to small changes in input.

Ridge Regression
What is ridge regression? Ridge regression is an extension of linear regression, and is particularly useful when we suspect the dataset has multicollinearity. What is this? We are now comfortable with the concept of regression, and have seen what simple linear regression is. This is very easy to imagine, i.e predicting housing prices from the crime rate in an area, for example. What about multiple predictor variables? That is, let’s consider multiple linear regression, where the model predicts the dependent variable using multiple independent variables.
This is good and all, until we consider the possibility of the IV’s have relationships between themselves and not being independent from each other, and this issue was mentioned in STAT231. multicollinearity refers to the above situation, where two or more predictor variables are highly correlated, causing problems in estimating the coefficients of the regression model, leading to unreliable and unstable estimates. To address this, we introduce a penalty for large coefficients. Let’s take a closer look at this.
With Ridge Regression, our loss function becomes:
Where lambda is the penalty, a non-negative hyperparameter that controls the amount of regularization. The term adds penalty for large coefficients, and scales with the value of . The choice of is crucial. If is too small, ridge regression behaves similarly to Ordinary Least Squares regression. If is too large, the model may underfit the data by shrinking the coefficients too much. Cross-validation is commonly used to find an optimal , which we will see later on.
By shrinking the coefficients, it reduces the variance introduced by multicollinearity, leading to more stable and interpretable models. Here is a simple image demonstrating this:
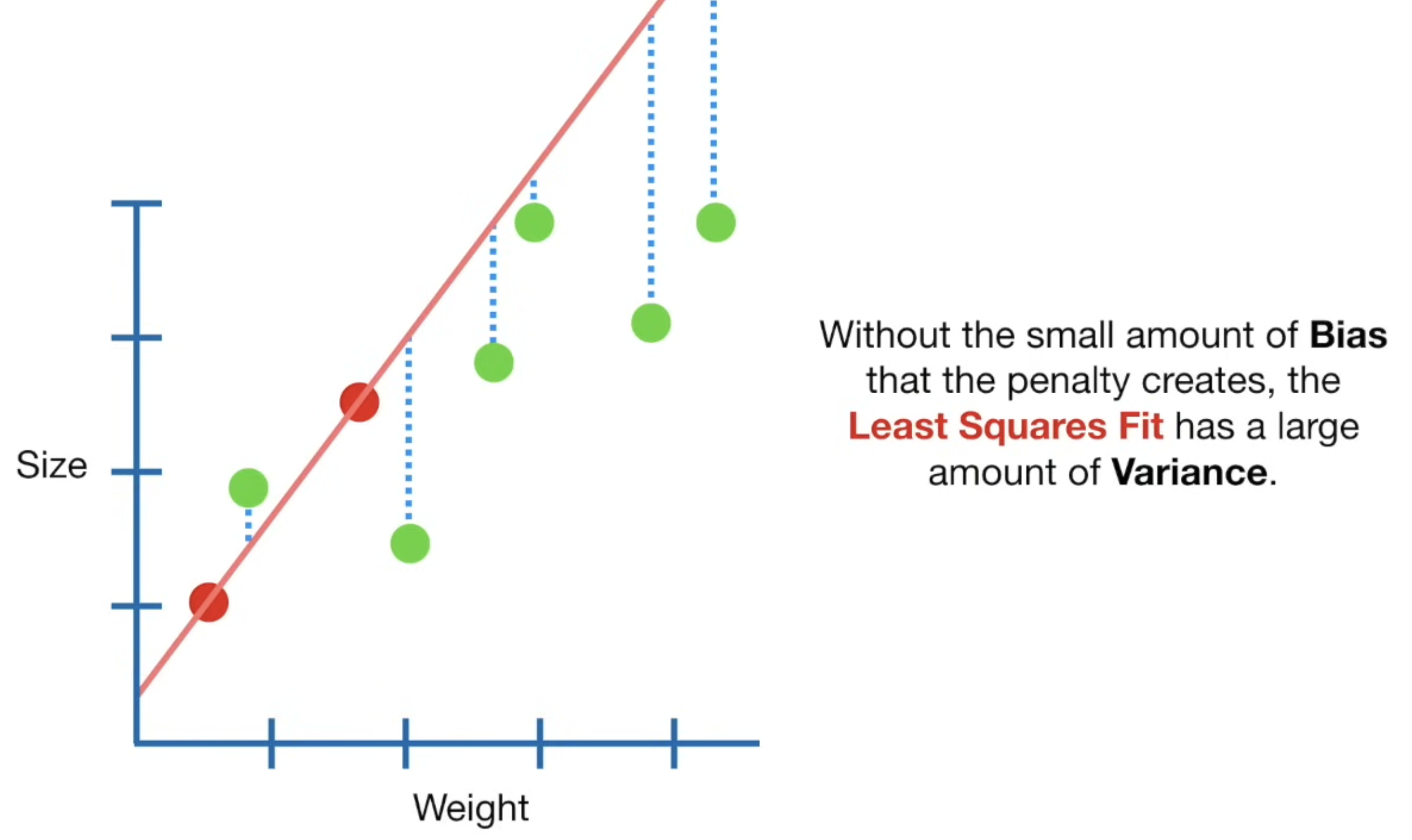
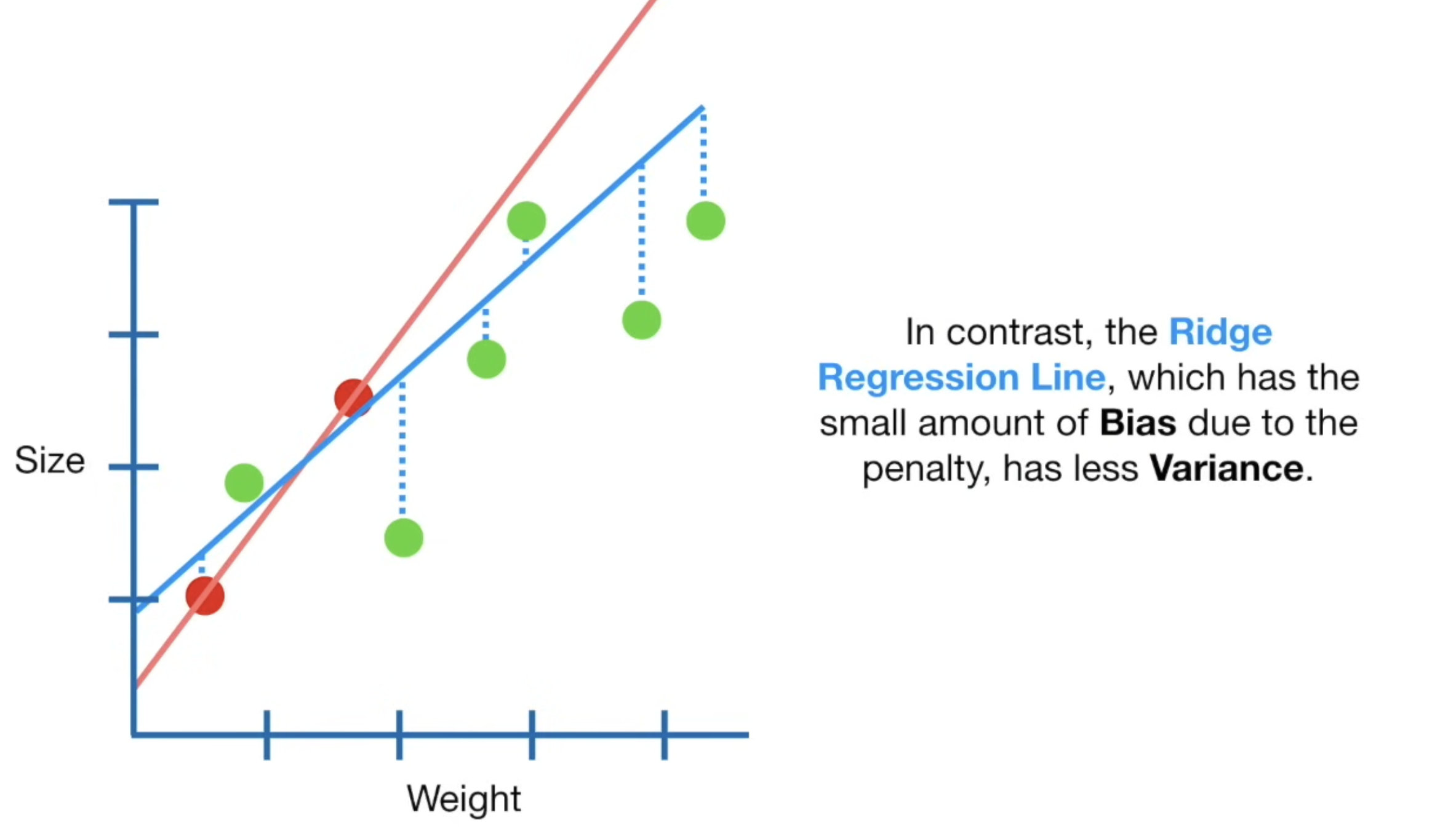
So now, the problem boils down to finding the weight , such that:
To summarize this section, we’ll take an excerpt from other notes again:

⇒ Data Augmentation
To combat the issues of small datasets and the risks that come with that (e.g training on the same sample twice), much like CNN’s, we can introduce data augmentation. For ridge regression, we can augment the sample and corresponding label as so:
- Augment with : i.e
- Augment with zeroes: i.e
This is how we can achieve regularization.
⇒ Cross Validation
Know, just skip.