BFS Application: Testing Whether a Graph is Bipartite
→ (Undirected) Bipartite Graphs and BFS
-
Recall that a graph is bipartite if the nodes can be partitioned into sets and such that each edge has 1 endpoint in and the other in
-
Upon first glance, its not always obvious if a graph is bipartite unless it is structured to show this attribute intentionally
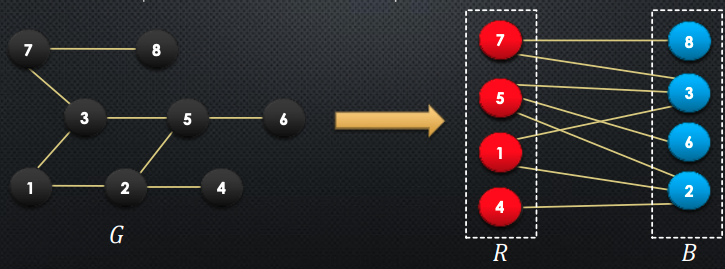
Claim: a graph is bipartite iff it does not contain an odd cycle
How to prove this? We prove this in both directions:
- → odd cycle ⇒ not bipartite
- Suppose for the sake of contradiction, that there an cycle of odd length:
- WLOG, suppose that , this then means that
- If we continue this until , we will notice that
- But, is adjacent to , and in order to be bipartite, they cannot both be in
- Therefore, arrived at a contradiction → qed
- ← all cycles have even length ⇒ bipartite
-
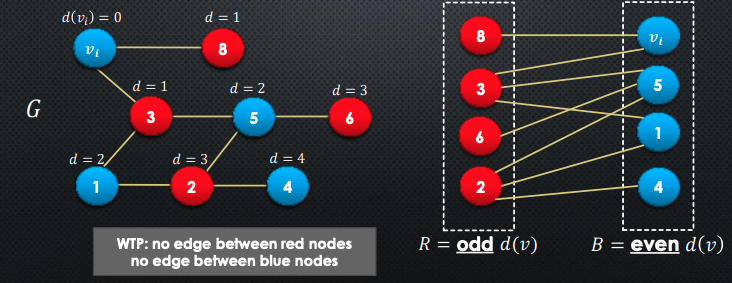
Let be any node, and to be the distance from to
-
We partition the rest of the nodes by even vs odd distances to
-
Claim: if there were any edges between red or blue nodes, there would be an odd length cycle.
To prove this, we can:
-
WLOG, suppose for contradiction where are red nodes
-
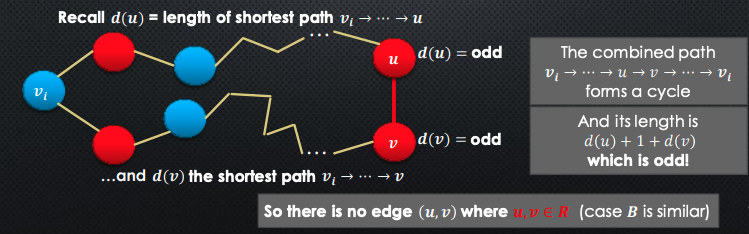
Since they are red, and from are both odd
-
So, what if we did have an edge between the 2 red nodes and ? We would then obtain an odd-length cycle.
With the information above, we can contruct an algorithm for testing bipartitness
def Bipartition(adj[1...n]):
colour[1...n] = [white, white, ..., white]
dist[1...n] = [infinity, infinity, ..., infinity]
for start in 1...n:
if colour[start] == white:
BFS(adj, start, colour, dist)
for edge in adj:
let u and v be endpoints of edge
if (dist[u]%2 == dist[v]%2):
return NotBipartite
B = nodes u with even dist[u]
R = nodes u with odd dist[u]
return B, R-
In the beginning, we create 2 lists: (1) for the starting colours of all nodes (2) distances from v_i
-
Then, we iterate over each node, and if white, we will perform a BFS on it. This is in case there are multiple components of the graph
- A bipartite graph can be unconnected
- An unconnected graph is bipartite if its components are bipartite
- Will only be one BFS run if the graph is connected
-
BFS calculates the distances for each node
-
This is a modified BFS → it re-uses the same colour array, same distance array
-
Once the entire graph has been explored, we will go trhough all edges in the graph, and check if the distances to each of the endpoints are both odd or even
- If so, then the graph is not bipartite
-
At the end, return the 2 partitions of nodes → and based on even or odd distance
→ What is the runtime of this algorithm?
Although we have BFS run inside of the for loop, they collectively will visit each node inside of the graph. So, this is just a work. Then, we iterate over all edges comparing the end nodes. We know there are edges and so, this is a operation. Lastly, we are constructing and which is . So, overall, the runtime of this algorithm is .
Depth-First Search (DFS)
-
Like the name suggests, instead of visiting all of the adjacent neighbours, we will visit a neighbour, and keep visiting one neighbour until we can no longer move on
-
DFS uses a stack (or recursion) instead of a queue
-
We define predecessors and colour vertices as in BFS
-
It is also useful to specify a discovery time and a finishing time for every vertx
-
We increment a time counter every time a value or is assigned
-
We eventually visit all the vertices, and the algorithm constructs a DFS forest
Here is the DFS algorithm (should be very familiar for you):
global variables:
pred[1...n] = [null, null, ..., null]
colour[1...n] = [white, white, ..., white]
d[1...n] = [0,0,...,0] # discovery times
f[1...n] = [0,0,...,0] # finish times
time = 0
def DepthFirstSearch(adj[1...n]):
for v in 1...n:
if colour[v] == white:
DFSVisit(v)
def DFSVisit(adj[1...n], v):
colour[v] = gray
time = time + 1
d[v] = time
for each w in adj[v]:
if colour[w] == white:
pred[w] = v
DFSVisit(w)
colour[v] = black
time = time + 1
f[v] = time - Let’s analyze the DFS algorithm
- In DFS, things like
predandcolourneed to be shared in every DFS call → we could make this pass by reference, but it is easier to make these things global variables - We create
dandfas our discover and finish times - We have
DepthFirstSearchas the outer function, since this is needed if our graph is directed or has multiple components. If the node is unvisited (white), we will calldfson it - The actual
DFSVisitfunction is the one performing the depth first search - We mark the current node we are on as gray, increment the time, and assign this as the current node’s discover time
- Then, for each unvisited neighbour node, we will assign their
predas the current node, and call DFS on them - After we have finished our DFS on all neighbouring nodes (a.k.a we have visited all reachable nodes from the current node), we mark the current node as black, indicating we are done processing it
- We assign the node’s finish time to
time

The above sequence of images demonstrates visually how the DFS works. In BFS, we saw that we constructed a BFS tree for connected graph (and BFS Forest for un-connected graphs). The same happens for DFS. In DFS, pred array induces a forest → here is how it is constructed/looks like:
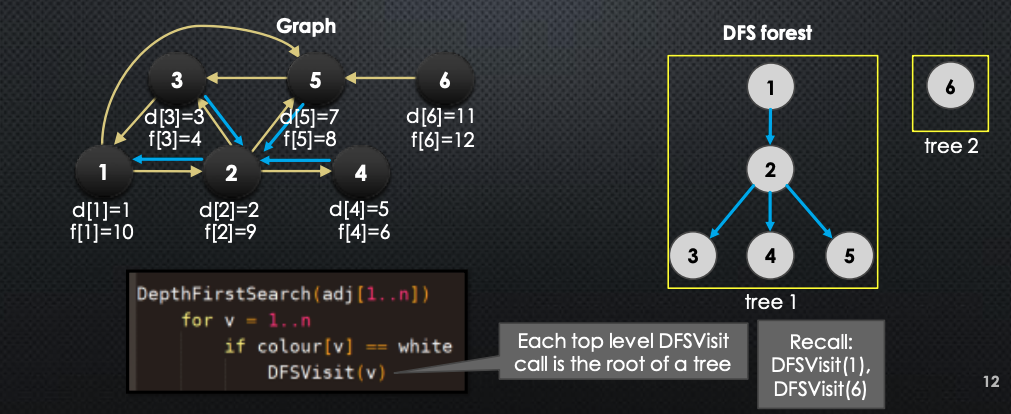
Here are some basic properties to remember:
- All nodes start out white
- A node turns gray when it is discovered (also gets a discovery time ) which is when the first call to
DFSVisit(v)happens - After turns gray, we recurse on its neighbours
- After recursing on all neighbours, we turn black → also gets a finish time
-
Recursive calls on neighbours end before
DFSVisit(v)does, so the neighbours of turn black before turns black
-
→ So, what is the runtime of the DFS algorithm?
-
In the beginning, we create the arrays we need to use →
-
We know that
DFSVisit(v)is only called on a node if it is white, so this function is called once per node.- Each call iterates over all neighbours. Effectively, for each node, for each neighbour, do work + recurse
-
Total iterations over all recursive calls → total is runtime
We classify the edges in DFS:
-
If
pred[v] = u, then is a ==tree edge==: That is u → v is called a tree edge -
Otherwise, there are 3 other cases:
- If is a descendent of in the DFS forest → ==forward edge==
- If is an ancestor of in the DFS forest → ==back edge==
- Else, is a ==cross edge==
-
Note that forward, back, and cross edges are not in the tree. Below is a good diagram of this:
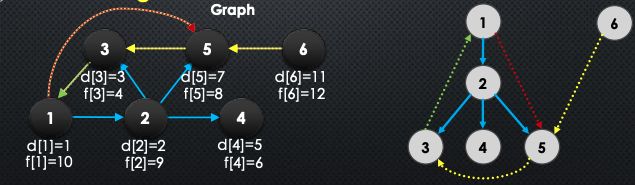
→ Some important definitions:
- We use to denote , which we will call the interval of
- We say “ is white-reachable from ”, if there is a path from to containing only white nodes (excluding )
-
So, we then say that a DFS call on will explore all the white-reachable nodes from . So in the below, nodes 1, 5 and 6 are white-reachable from node → the nodes that will be discovered from the DFS call on
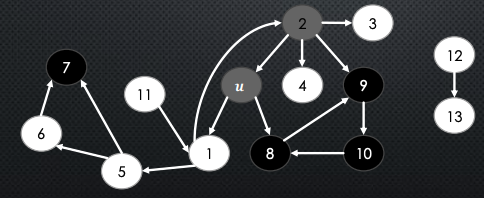
-
Observe: every node that is white-reachable from when we first call
DFSVisit(v)becomes gray after and black before . This means that is nested inside . This should be very understandable.
So, as a quick summary, we conclude with the following theorem:
→ Theorem: let be any nodes in the graph. The following statements are all equivalent:
-
is white-reachable from when we call
DFSVisit(u) -
turns gray after and turns black before
-
discovery/finish time interval is nested inside of
-
is discovered during
DFSVisit(u) -
is a descendant of in the DFS Forest
Throughout the DFS algorithm, the DFS inspects every edge in the graph. When DFS inspects every edge , the colour of and relationship between the intervals of and determine the edge type. The following table summarizes this nicely:

So, what is this saying? Based on the theorem above, consider the edge between and . If it is a:
-
tree edge u→v: then, we know that is a child of in the DFS tree, and so, we know that is white
-
forward edge: then, we know that is a descendent of in the DFS forest. This means that we full process before returning to . Hence, it is black
-
back edge: then, we know that is an ancestor of . So, this means that when calling
dfson , we eventually reached and it points back to . This means that is gray, as it has no completed yet. We’ve discovered but we have not finished it → so gray -
What about cross edge? We do not know, the above theorem is not capable of handling this case. This is because for this, is neither a descendent or ancestor of . We need additional information
Useful Fact: Parenthesis Theorem → For each pair of nodes the intervals of and are either disjoint or nested. So, there are no intervals with overlaps.
→ Proof:
- Suppose the intervals are not disjoint → there is some overlap
- Then either or
- WLOG, suppose that
- This then means that is discovered during
DFSVisit(u), so, must turn gray after and black before . - So, this means that
- This means that the intervals are nested
With this theorem, we revisit the image above. We can quikcly come to the conclusion that it is not nested → as this would imply that either is a descendent of or vic versa. So, they have to be disjoint. The question is, which one is earlier? As there is an edge from → , we cannot let the start time of occur before , as it would then visit , making these intervals not disjoint. We revisit the above diagram to better visualize this:
Application of DFS (or BFS)
→ Strong Connectedness
- In a directed graph:
- is reachable from if there is a path from to
- We denote this path with whereas an edge would be denoted
- A graph is strongly connected iff every node is reachable from every other node. More fomally →
Below we give an example:
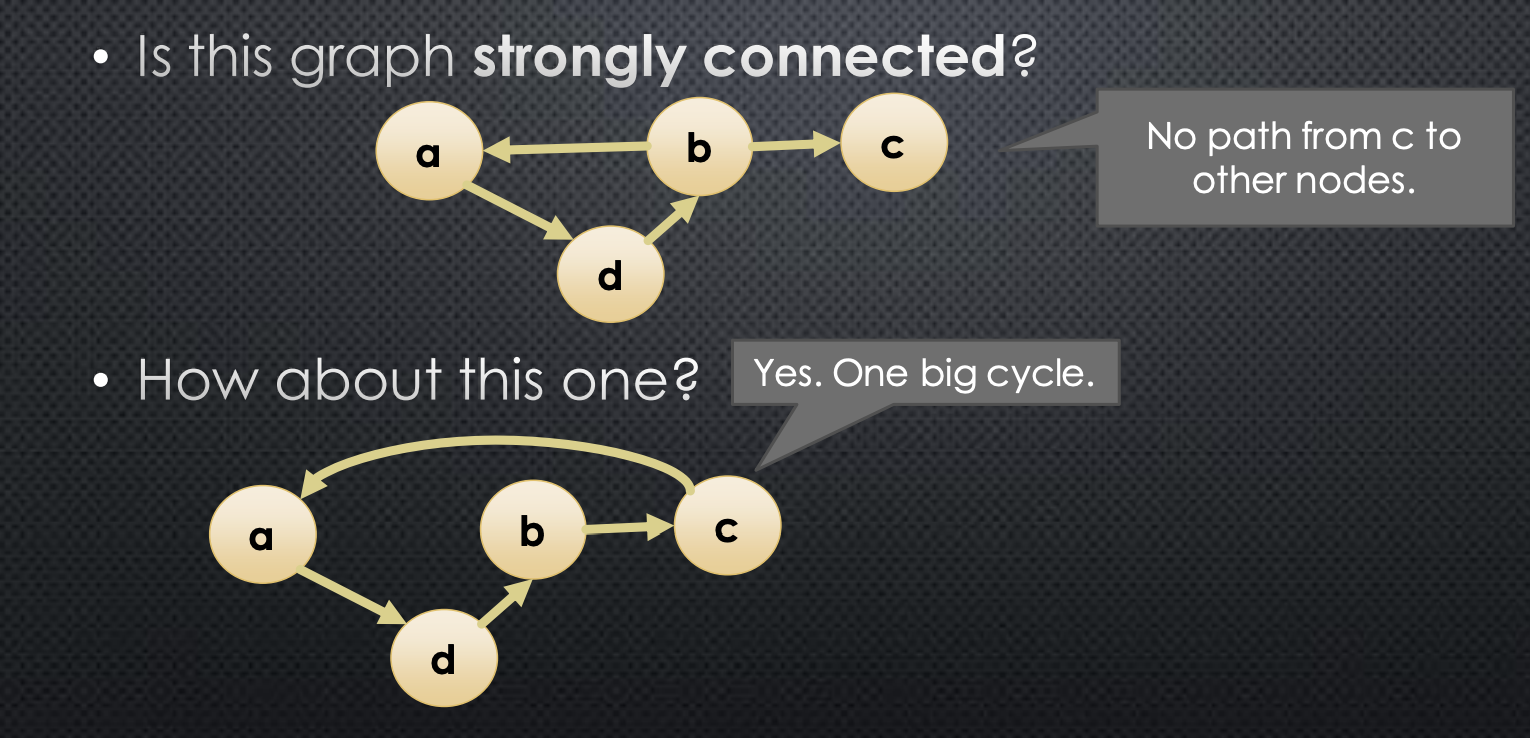
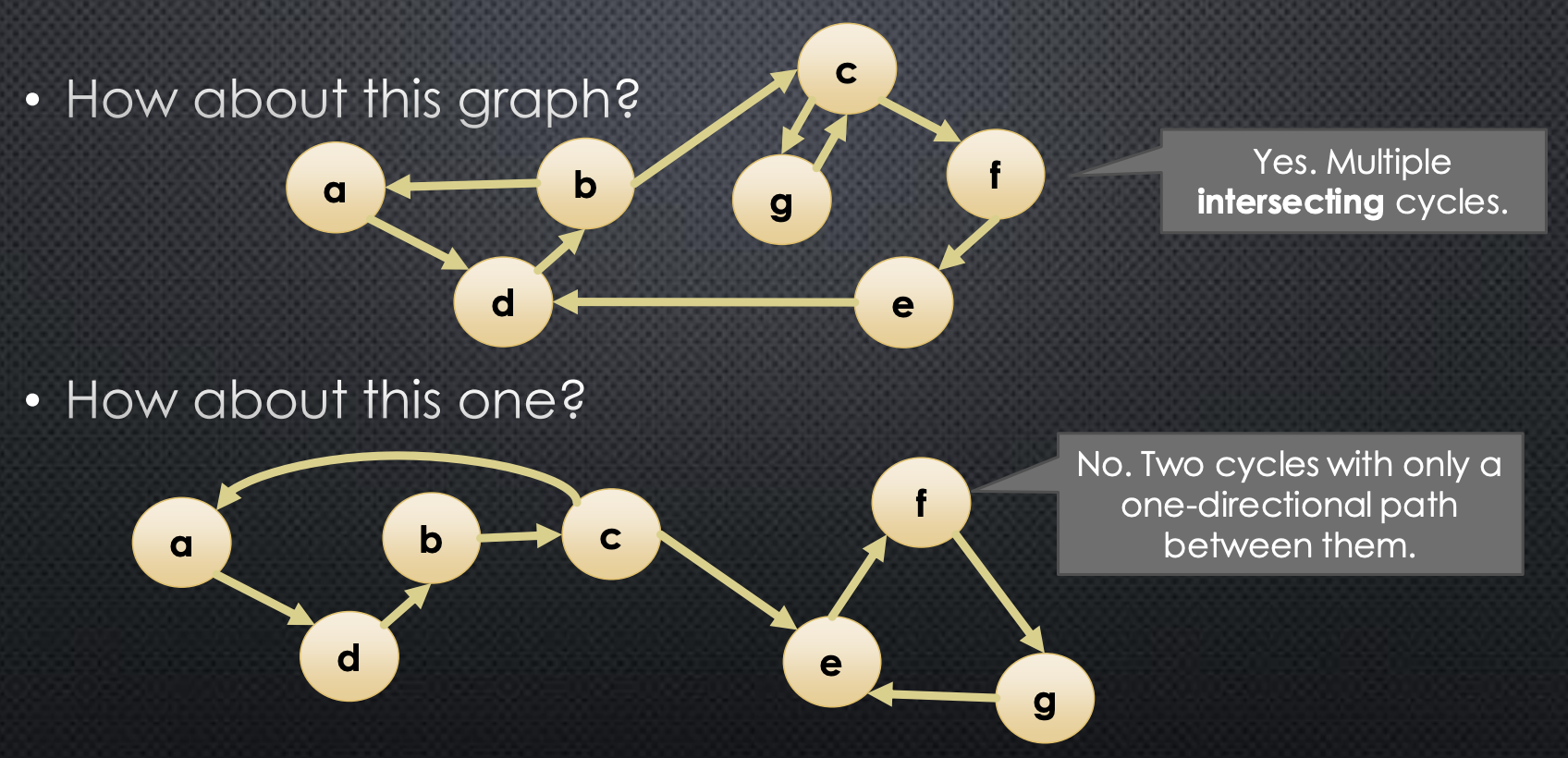
So, what do we gain from knowing that a graph is strongly connected? For example, we can start a graph traversal at any node, and know the node will reach every other node. Without strong connectedness, if we want to run a graph traversal that reaches every node in a single pass, we would need to do additional processing to determine an appropriate starting node.
Another instance of this being useful is as a sanity check. Suppose we want to run an algorithm that requires strong connectedness and we believe out input is strongly connected. It may be advised to verify that our input is indeed strongly connected. So, perhaps we can use DFS to accomplish this? We ask ourselves:
- How to use DFS to determine whether every node is reachable from a given node
- Perform a DFS from node and see if every other node turns black
- How to use DFS to determine whether is reachable from every node
-
This is interesting. The naive approach would be to perform a DFS on every other node, and see if all of them are able to reach . This is far from ideal, as it results in a run time.
-
A clever, and way of doing this is to reverse the direction of all edges. Why would this work? If there was a path from arbitrary node to , then reversing the edges in this path essentially inverts the direction of the path. So now, we need to see if there is a path from to in graph, say — graph reversed, which becomes the first bullet-point.
-
Here is what the algorithm will look like:
def isConnected(G):
V, E = G
(color, d, f) = DFSVisit(V[0], G)
for i in 1...n:
if color[V[i]] != black:
return False
H = reverseGraph(G)
(color, d, f) = DFSVisit(V[0], H)
for i in range(1, len(V) + 1):
if color[V[i]] != black:
return False
return TrueHow would we go about reversing the adjacency array? We will show this for the adjacency matrix. Turn out, its just computing the transpose of the adjacency matrix.
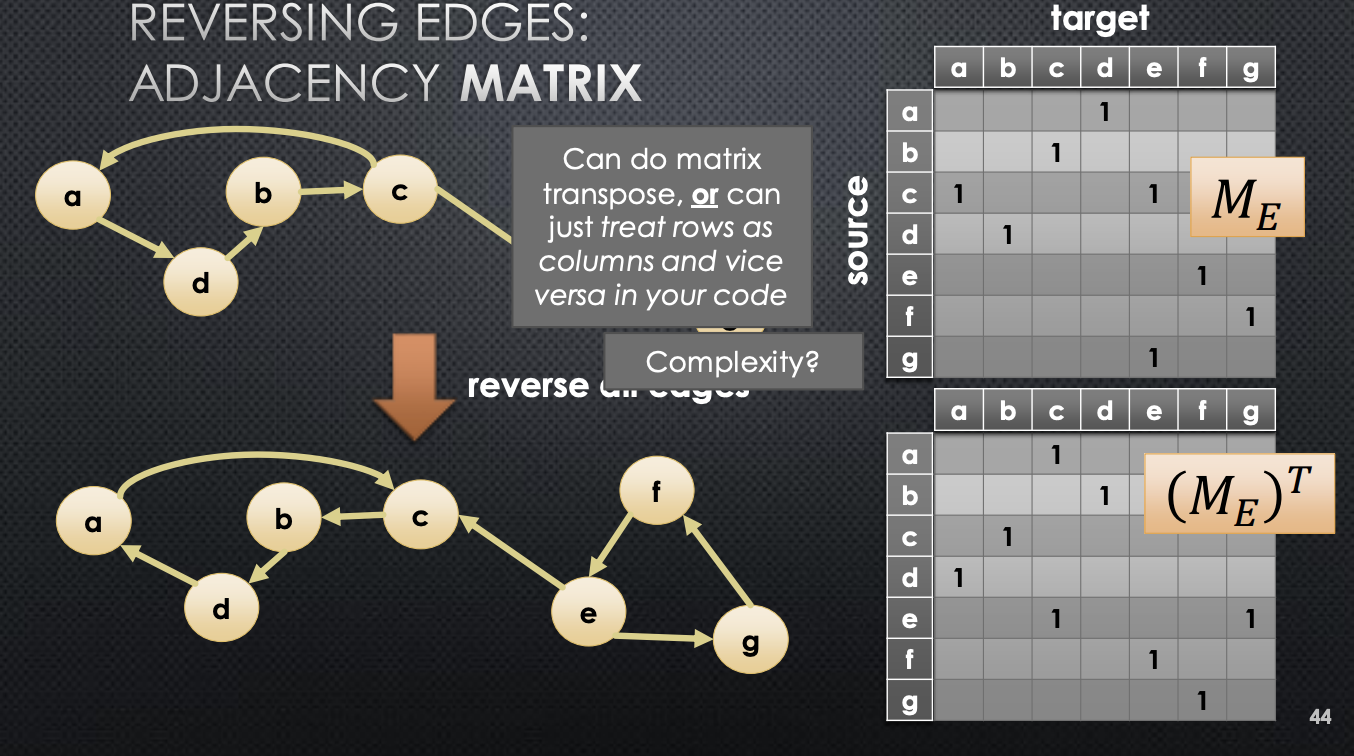
This is actually slightly expensive. We will need to look into each cell to know how to flip → this is complexity. What about reversing adjacency lists? Very straightforward. We construct a new adjacney list, and iterate through every list in the original one. Something like:
def TransposeLists(adj[1...n]):
newAdj = new array of n lists
for u = 1 ... n:
for v in adj[u]:
newAdj[v].insert(u)
return newAdjThe runtime of this is . So, this is prefered as using this will not affect the total runtime of checking if a graph is strongly connected. Therefore, the above algorithm, using a adjacency list, as run-time .